
GAMS and Cirilo Client: Policies, documentation and tutorial
Elisabeth Steiner & Johannes Stigler
First released: 2014
Last update: 2022-06-28
Handle: hdl:11471/521.1.1
Table of contents
- About
- Content models
- Tutorial: First steps
- Tutorial: Advanced
- How to use GAMS as an annotation framework
- References
About
GAMS
Since 2003 the Centre for Information Modelling - Austrian Centre for Digital Humanities provides an infrastructure for a variety of Digital Humanities projects. After years of building insular solutions, the Centre introduced a powerful yet flexible new infrastructure, called GAMS (Geisteswissenschaftliches Asset Management System, AMS for the Humanities). It is based on the FEDORA Commons architecture and thus inherits all features already provided by this project. FEDORA (Flexible Extensible Digital Object Repository Architecture) is an infrastructure dedicated to the persistent archival and management of resources considered to be worthy of long-term preservation.
Cirilo
Cirilo1 is a java application developed for content preservation and data curation in FEDORA-based repository systems. Content preservation and data curation in our sense include object creation and management, versioning, normalization and standards, and the choice of data formats. The client offers functionalities which are especially prone to be used as tools for mass operations on FEDORA objects, thus complementing FEDORA's inbuilt Admin Client. Cirilo operates on FEDORA's management-API (API-M) and uses a collection of predefined content models. These content models can be used without further adjustments for standard workflow scenarios like the management of collections of TEI objects. Content models in the sense of FEDORA are class definitions; On the one hand they define the (MIME-)type of the contained datastreams, on the other hand they designate dissemination methods operating on these datastreams. Every object in the repository is an instance of one of these class definitions.
In the following, a few basic concepts and their implementation in the GAMS will be introduced. The provided background information will be useful to understand the benefits of the client and the underlying infrastructure.
Basic concepts
Long-term preservation
Long-term preservation denotes the process of maintaining, curating and keeping data usable over a long period of time. Long-term preservation is especially important in the case of scientific and cultural heritage data or digital objects and can be achieved in various ways; for instance by the use of open and sustainable data formats, employing reference models and monitoring technical change. In this context, repositories are system architectures responsible for the management and preservation of digital resources. Key functionalities of these architectures include persistent identification, versioning, support of different data formats, management of associated metadata, data export and retrieval, security and scalability. Special emphasis is placed on sustainability, citability and guarantee of long-term access to the contained resources. Consequently, data formats and software used for preservation should follow open source and non-proprietary standards; data is ideally encoded in an unicode XML format. One possible organisational principle for repository systems is an asset management system (AMS). Originally coming from economics, an asset denotes an organisational principle. It is the smallest unit administered by the repository system. A digital object identified as an asset usually consists of more than one file, such as primary data, metadata, etc. GAMS and Cirilo expecially exploit the opportunities provided by FEDORA's object model (see here for more information).
OAIS reference model
For the complex process of long-term preservation, reference models are used to give an overview of required functions and workflows of an archive. These abstract models describe the relationships and tasks of the involved organizations and serve as a blueprint for the appropriate workflow and curation process. The most important reference model for long-term preservation is the Open Archival Information System (OAIS) reference model, first introduced by the Consultative Committee for Space Data Systems (CCSDS). It describes the steps of acquiring, ingesting and accessing information packages in a digital archive. The main functions are summarized in this figure.

The central components in the reference model are information packages. On a conceptual level these roughly correspond to digital objects and assets. Information packages enter the process of long-term preservation as Submission Information Packages (SIP), which are submitted to the archive by the producers. SIPs are transformed into Archival Information Packages (AIP) and then ingested and stored in the archival storage. During this transformation the information package is adapted to the requirements of the digital archive and receives its persistent identifier (PID). When a consumer is requesting a resource, the AIP is changed into a Dissemination Information Package (DIP), optimized for access of the user. The whole procedure is naturally accompagnied by an administration layer and the important function of preservation planning. A digital archive or repository conforming to the OAIS standard is termed OAIS compliant. FEDORA as a repository system provides all mechanisms and technical requirements to be used in an OAIS compliant way, thus also making GAMS an OAIS compliant repository.
Trust
Apart from compliance to the OAIS reference model, the notion of trusted digital repositories has gained ground in the discussion on long-term preservation. In opposition to physical libraries and archives which have been working on their trusted reputation for centuries, digital organisations often face problems regarding their reliability. 'Trust' is used for the positive attitude of the potential users towards the digital archive, assuming that the provided resources are authentic and unmodified in comparison to their original or physical shape. There are several sets of recommendations defining best practice in repositories leading them to be perceived as trustworthy. Known certification checklists include DRAMBORA (Digital Repository Audit Method Based on Risk Assessment), the Data Seal of Approval, and nestor (Network of Expertise in Long-term Storage and Availability of Digital Resources in Germany).
Since 2014 GAMS is a certified trusted digital repository in accordance with the guidelines of the Data Seal of Approval.
Persistently identified objects and metadata
Two topics are especially vital for the creation of valuable digital objects, namely persistent identification and enrichment with metadata. Assigning PIDs to resources is crucial when working with scientific and cultural heritage materials, because it ensures availability and citability of the resources. Widely known persistent identifier systems include DOI (Digital Object Identifier), URN (Uniform Resource Name), PURL (Persistent Uniform Resource Locator) or handle. The Centre for Information-Modelling is member of the handle network and is running its own handle server, the prefix is 11471. The client can generate a unique handle for each object. This persistent identifier is stored as part of the objects' metadata and is published in the handle infrastructure.
Associating metadata increases the (re-)usability of data objects and enriches the primary resource with further information. This is also called markup, where markup can stand for any information added to the primary resource. Every object should be enriched with metadata in widely acknowledged standards to provide basic metainformation. The most important set of such standardized basic metainformation is known as Dublin Core (DC). The Dublin Core Metadata Initiative is maintaining this standard, which has become the main exchange and harvesting format for digital archives. Therefore, DC is especially prominent in the Cirilo client. The main framework for text encoding is the Text Encoding Initiative (TEI) standard. This XML-based framework enables users to annotate their text in a highly standardized yet flexible way which ensures interoperability and reusability of the data. The client offers a content model specifically dedicated to the representation of TEI documents. Another influential institution is the Open Archives Initiative, which offers with the Protocol for Metadata Harvesting (OAI-PMH) a standardized way of harvesting metadata from repositories.
Data security
To ensure physical persistence of data in case of hardware errors or disasters it is necessary to have a data security policy in place. Data storage for GAMS is provided via SAN by the University’s IT department (UNI IT). Data is stored redundantly in two data centers in different campus buildings. Data backup in GAMS is part of the central backup processes of the University. Backups run daily and are stored on a disk array and later moved to tape. There is an additional offsite backup managed by the Centre which is also run every night. The combination of both backups ensures their accessibility over a period of seven years. Backup consistency is guaranteed because every FEDORA object is entirely stored in FOXML format containing all binary data streams in base64 encoding. Additionally, all datastreams are preserved in the original format as distinct files. As each object provides MD5 checksums for the datastreams, corrupted data can be identified easily. Data recovery is regularly exercised on a spare machine for training purposes of the administrators.
Getting Started: requirements, download, authentication and licensing
The client is tested with FEDORA versions 3.x except for 3.7. There are two possibilities for the installation: a) You can start the client directly from a browser using the java web start option (Java Runtime Environment required) under the URL https://gams.uni-graz.at/cirilo/2.0. There you always receive the most recent version of the client. b) The second option is to download the source code from Github (https://github.com/acdh/cirilo) and start it locally. When the login dialog appears, simply enter the login and authentication information of your own repository instance:
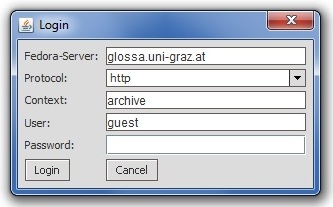
In the first field, enter the server of your FEDORA repository. In the second field, choose the protocol you want to run your data connection with. "Context" is the application context (root folder) in which the FEDORA process is running in the Tomcat servlet container (usually 'FEDORA'). These parameters can be provided by your system administrator. Then enter your user name and password. Cirilo authentication can be based on the FEDORA internal authentication mechanism, but other possibilities can as well be configured to work with Cirilo (e.g. LDAP, Shibboleth, etc.). Cirilo is an open source software, the reference to the open source license is contained in the source code of the client and can be found here: http://opensource.org/licenses/Apache-2.0. All login data except the password are stored in the file cirilo.ini (to be found in the home directory of the user) and therefore available for the next starting process. The client language can be determined by choosing a language in the cirilo.ini file (currently German ("de") or English ("en")) (see Tutorial: First steps).
The use of the import option enables you to use the content models provided by the Cirilo client with your own FEDORA repository instance. You can download the needed files in FOXML format from GitHub (https://github.com/acdh/cirilo). The folder 'objects' contains the class description of all content models (starting with 'cm'), service definition objects (starting with 'sdef') and service deployment objects (starting with 'sdep') in the client (cf. also the section on different types of objects in FEDORA). The folder 'templates' contains the instances of these classes, which are used as a template for the creation of new objects. To take over the Cirilo content models into your own FEDORA repository, download the files in both folders to a location on your local file system. Then choose the 'File' > 'Import objects' option and select that location from the filesystem and all files are imported. The Cirilo client will replace all URLs in the FOXML pointing to a server location starting with https://gams.uni-graz.at or https://glossa.uni-graz.at with the URL of your own FEDORA repository installation. Thus, the content models will be completely adapted to your own repository environment after the import process.
If you experience problems with the correct display of characters (like German umlaut) in the client, go to the Java settings on your computer (control panel > Java). There, go to Java Runtime Environment settings and enter in the parameter field "-Dfile.encoding=UTF8".
Content models
This section contains information on some default and automatically generated components of a) the object model of the underlying FEDORA repository and b) the specialized content models of the Cirilo client. It is stressed that new models and datastreams can be added and the existing ones can be changed; this is only a description of the components provided by default.
FEDORA and its object model
FEDORA has established itself as one of the most widely used solutions for the handling of scientific and cultural heritage data. Originally, it has been developed by the Universities of Virigina and Cornell and is now maintained by the collective FEDORA Commons. The system is platform-independent, open source and supports versioning. The contained data can be dynamically transformed and viewed, ideally supporting the separation of form and content (single source publishing). The framework is constructed completely on XML standards and offers great flexibility with regard to the treated data objects. Key functionalities include:
- management and administration of internal and external data sources
- URL-based access to the objects and their components
- version control
- RDF-based full text index
- decentralized system architecture based on SOAP
- flexibly configurable access rights based on XACML
- standardized import and export formats
- support of OAI-PMH metadata harvesting
FEDORA uses an object-oriented repository approach, where the object is called asset. A minimal asset consists of the primary datastream and a metadata set encapsulated by one mutual PID. The internal structure of the asset can vary according to its primary data (text or image for instance) and is determined by its content model. The content model comprises information on the primary datastreams, the contained metadata set(s) and already defined retrieval/dissemination methods.
The following figure clarifies the compound digital object/asset. The example consists of 3 datastreams, each of them representing the object differently; as a metadata record in Dublin Core format and two image formats with different resolution. All components are kept together by their mutual PID.

The second figure shows the addition of a virtual representation of the object, i.e. a dissemination method; in this case for the high resolution image. A service operation takes the image datastream as an input and creates a zoom functionality.

The FEDORA digital object model distinguishes different types of digital objects, treated differently by the system.
- Data objects are the ones containing the primary data.
- Service definition objects (SDef) carry out a service operation.
- Service deployment objects (SDep) are special SDefs containing processing instructions for the operations.
- Content model objects (CModel) contain the aforementioned structure of an asset.2
Content models in Cirilo
Cirilo takes advantage of FEDORA's object model approach by providing default content models. These models are designed for different types of primary data and can be used without modification. They are customized to fit some common standards such as the TEI or METS (needed for the DFG-Viewer). Content models can only be altered by the administrator of the repository and are therefore not visible or editable in the client for the default user.
Before proceeding to the individual datastreams and features of each content model, some datastreams available in all content models will be shortly introduced.
FEDORA requires every object to have at least one system datastream, namely a Dublin Core (DC) record.
- The DC datastream3 contains all available Dublin Core metadata for that resource in an OAI-PMH compliant XML-format, either coming from the information entered manually in the DC dialogue box in the client or extracted automatically from the source document via the DC_MAPPING datastream.
The underlying structure of the Cirilo Client requires the presence of some other datastreams to function properly, namely a RELS-EXT record, a THUMBNAIL, a STYLESHEET and FO_STYLESHEET, a BIBTEX and a QUERY stream. Consequently, these datastreams are created automatically by the client upon creation or ingest of an object.
- RELS-EXT is short for 'relationships-external' and contains information on the object itself and relationships to other objects in a FEDORA specific RDF-implementation. The information is stored in FEDORA's internal Mulgara triplestore.
- THUMBNAIL contains a thumbnail representing the resource; if not otherwise specified a default image is used. For the TEI model, the first <graphic>-element in the source is down scaled and functions as the thumbnail.
- STYLESHEET is responsible for transforming the primary source of an object to an HTML representation with the help of an XSL stylesheet.
- FO_STYLESHEET contains an XSL-FO transformation responsible for the view of the primary source as a PDF document.
- Every content model is equipped with a BIBTEX content datastream; BibTex is a (free) bibliographic management format. In the cirilo:dfgMETS model the information in the BIBTEX stream is extracted automatically by means of the MODStoBIBTEX_Mapping of the cirilo:Backbone object (cf. the section on the initializer object). In other models, the BIBTEX stream contains an empty default structure, where you can enter the appropriate bibliographical record manually.
- QUERY contains a query to the Mulgara triplestore for various system information of the object, like update dates. The result is displayed in the METADATA stream only visible in the FEDORA search interface. The query format is the SPARQL query language for RDF triples (cf. SPARQL Query Language for RDF). This applies to all content models but the cirilo:Query content model, where the QUERY datastream has another meaning.
- QR contains the JPG representation of the QR (Quick Response) code of the resource (http://www.qrcode.com)
Datastreams present in all content models
- DC
- RELS-EXT
- THUMBNAIL
- STYLESHEET
- FO_STYLESHEET
- BIBTEX
- QUERY
- QR
All other datastreams are specific to the respective content model. The following sections give an overview of these models and explains their peculiarities apart from the just described common datastreams.
cirilo:Annotation
This content model is used to store anntotations compliant with the Open Annotation Data Model, the PID starts with 'o:oao'. The annotation itself is stored in the BODY datastream, the datastream TARGETS contains the list of targets of the annotation. Selected text passages or zones of the target(s) are given in the datstream SELECTORS. ANNOTATION contains a summary of the primary information on the anntotation. More information on how to use GAMS as an annotation framework can be found in the respective section.
cirilo:BibTeX
cirilo:BibTeX is used for objects where the primary source is a BibTeX document stored in the BIBTEX datastream. You can enter data in BibTeX format or BibTeX XML format, the client can use both. In the STYLESHEET and FO_STYLESHEET datastreams you can find the default transformations for the representation of BibTeX in HTML and PDF respectively.
cirilo:Context
This content model is used for the creation of a context object, that allows the creation of collections (cf. the section How to organize collections). Context objects can gather geo information from their assigned data objects in Keyhole Markup Language (KML) format. KML_TEMPLATE contains a default mapping for the automatic extraction of KML data (for a detailed description see this section). KML_REF contains the reference for the call of the GAMS KML Viewer coming with the client. Context objects can show maps in three ways: a) by using the GAMS KML Viewer (sdef:Map/get), b) by using the PLATIN Place and Time Navigator (sdef:Map/getPlatin) and c) by using the DARIAH-DE GeoBrowser 4 (sdef:Map/getDariah). STYLESHEET contains a default stylesheet for the representation of the context in HTML, FO_STYLESHEET for PDF. QUERY specifies the search properties for the Mulgara triplestore, the result is visible in the METADATA datastream (only available in the FEDORA search interface). The default query saved in the content model will be applied to all new context objects. A sample query can look like this:
select distinct * where { <$self> <dc:title> ?container . <$self> <dc:identifier> ?cid . ?pid <fedora-rels-ext:isMemberOf> <$self> . ?pid <fedora-model:hasModel> ?model . ?pid <fedora-model:ownerId> ?ownerId . ?pid <fedora-model:createdDate> ?createdDate . ?pid <fedora-view:lastModifiedDate> ?lastModifiedDate . ?pid <dc:title> ?title . ?pid <dc:identifier> ?identifier . optional { ?pid <dc:description> ?description} . optional { ?pid <dc:subject> ?subject} . filter regex(str(?model), "^info:fedora/cm:") }cirilo:dfgMETS
This content model is used for XML objects conforming to the METS/MODS standard used by the free DFG-Viewer. The primary data is stored in the METS_SOURCE, containing a METS/MODS document complying to the requirements of the DFG-Viewer; URL contains the function call to the viewer. The viewer was developed by the German Science Fund (Deutsche Forschungsgemeinschaft - DFG) for viewing manuscripts and printed materials. It offers a range of basic metadata, page turning and zoom options and a table of contents for navigation within the resource. DC_MAPPING contains the metadata crosswalk for creating DC metadata from the METS/MODS file. The BIBTEX datastream contains the citation of the resource in BibTeX format, extracted from the source document by the BIBTEX_MAPPING. It is also possible to create cirilo:dfgMETS objects from TEI documents, which enables you to store METS/MODS and TEI documents in the same object and to use the dissemination methods of both content models (cf. this section).
cirilo:HTML
cirilo:HTML is used for the creation of an object where the primary source consists of HTML markup. The source is stored in the HTML_STREAM datastream.
cirilo:LaTeX
cirilo:LaTeX is used for objects containing a LaTeX document. It is stored in the LATEX_STREAM datastream.
cirilo:LIDO
The cirilo:LIDO content model is used for digital objects where the primary source is a LIDO document; it is stored in the LIDO_SOURCE. LIDO is a CIDOC-CRM conform standard for the description of museum objects. Thus, cirilo:LIDO can be used for the description of artefacts in the same way that cirilo:TEI is used for the annotation of textual material. You can also integrate TEI annotations in your LIDO document; you can use the TEI LITE subset in every <lido:descriptiveNoteValue> element. The DC_MAPPING and TORDF datastreams are applied for the extraction of DC data and RDF triples. STYLESHEET and FO_STYLESHEET contain XSL transformations for the creation of HTML and PDF output. You can semantically enrich your LIDO objects (cf. How to semantically enrich your data) and configure the ingest process (cf. Extras - Preferences).
cirilo:MEI
The cirilo:MEI model contains a primary source in MEI format in the MEI_SOURCE datastream. Using the STYLESHEET transformation, you can create HTML output. The default get method is the output of SVG, but also PDF is possible.
cirilo:OAIRecord
The client can act as an OAI harvester. A cirilo:OAIRecord object contains the result of such a harvesting process. The RECORD datastream contains the harvested data source, which has to be a OAI 2.0 compliant XML. The URL datastream contains the complete external reference to the harvested object (cf. this section).
cirilo:Ontology
This content model has an RDF/XML structure as primary data source which is stored in the ONTOLOGY datastream. REPOSITORY contains the reference to the location of the Sesame repository where cirilo:Ontology and cirilo:SKOS objects are stored. It is good practice to keep semantic models (namely Ontology and SKOS) separate from the others in a Sesame repository, because it offers the possibility to use SPARQL 1.1. SPARQL 1.1 in turn is needed, because it enables you to query multiple sources at the same time (cf. How to semantically enrich your data). The STYLESHEET and STYLESHEET_FO datastreams in the ontology content model are empty, because it is not feasible to provide default stylesheets for ontologies.
cirilo:PDF
cirilo:PDF is used for objects containing a PDF document. It is stored in the PDF_STREAM datastream.
cirilo:Query
The query content model contains a SPARQL query to the Mulgara triplestore as its primary source. It is similar to the cirilo:Context object in the respect, that it selects some objects and shows this selection according to the STYLESHEET, except that the results of the query are displayed and not the members of the context. One possible use case for this model is for instance the creation of dynamic indices (cf. How to semantically enrich your data). To export and analyse SPARQL query results as spreadsheet data, see this section.
cirilo:R
The content model cirilo:R can contain code in the language R or Python in the RSCRIPT datastream. The object encapsules statistical analysis functionalities and can be used for network analysis or topic modelling scenarios (cf. this section).
cirilo:Resource
Cirilo:Resource is used for the reference to any HTML resource accessible via an URL, which is also the primary datastream of the resource. The information accessible via the URL can be displayed either with the STYLESHEET (in this case responsible for the representation as BibTeX record only) or the FO_STYLESHEET (in PDF).
cirilo:SKOS
cirilo:SKOS is basically an ontology content model optimized for the use of SKOS and providing the appropriate methods for SKOS ontologies. The SKOS ontology is stored in the ONTOLOGY datastream, the content is managed in an OpenRDF Sesame Repository (cf. How to semantically enrich your data). In the 'Preferences' you can choose to normalize your SKOS annotation with the Skosify webservice.
cirilo:Story
This content model can be used to create virtual walks or tours through collections. It makes use of the free tool StoryMapJS. The datastream STORY contains an XML structure which is automatically converted to JSON for the tool input. Follow the documentation of StoryMapJS to create valid markup. You can use the output fullscreen as it is or customize and embed it with a STYLESHEET datastream into your website.
cirilo:TEI
This content model is used for the creation and management of objects where the primary source is a TEI document; it is stored in the datastream TEI_SOURCE. DC_MAPPING contains the crosswalk extracting DC metadata from the TEI document and saving it to the DC stream (cf. the section How to semantically enrich your data). RDF_MAPPING produces RDF triples from the TEI source and stores the result in the RELS-INT datastream. TORDF also extracts RDF triples from the TEI source but stores it directly to the Sesame repository and a copy of it to the RDF datastream (cf. the section How to semantically enrich your data). REPLACEMENT_RULESET contains the reference to a set of regular expressions (regex) replacements (see this section for a description and example). The default STYLESHEET stream for TEI objects contains an XSL transformation that creates an HTML representation of not only the TEI_SOURCE itself, but also of the BIBTEX record of that object. When calling the sdef:BibTeX get-method, FEDORA adds the parameter $model with the value 'BibTeX' (case sensitive). By utilizing this parameter, it is possible to define separate rules for the representation of the BIBTEX stream in HTML-format. Accordingly, the default FO_STYLESHEET for TEI objects contains not only the information for representing the TEI_SOURCE in PDF, but also the BIBTEX stream in PDF format. When calling the sdef:BibTeX getPDF-method, FEDORA adds the parameter $model with the value 'BibTeX' (case sensitive). By utilizing this parameter it is possible to define separate rules for the representation of the BIBTEX stream in PDF-format. Another possibility to create print output is the use of LaTeX. To this end, create and update the datastream LATEX_STYLESHEET and call the method sdef:TEI/getLaTeX. A special case of STYLESHEET is the use of the Versioning Machine. This is a tool for the comparison of more than one version of a text. The input is an appropriately annotated TEI document containing the markup of all text witnesses to be compared, the output is an environment for analysing and visualising the digital edition. To add the Versioning Machine as a dissemination method you have to assign the needed XSLT-stylesheet through a replacement operation to the object(s) in question (cf. also the sections on replacement of object contents). This stylesheet can be found in the cirilo:Backbone object (cf. the section on the initializer object). VOYANT contains the call to the Voyant Tools web service. With the help of the Voyant Tools you can not only analyse but also visualize your digital texts. The ingest process of TEI objects can be customized in the section Extras - Preferences. It is also possible to combine the methods of the cirilo:TEI model with the cirilo:dfgMETS model (cf. this section). To export and analyse information from the TEI as spreadsheet data, see this section.
The FEDORA web interface and adressing conventions
The internal structure of a FEDORA repository and its objects can be explored through the 'Search Repository' function; also referred to as FEDORA search or web interface. This browsing function is available at 'servername/context/search', where 'context' once again stands for the application context (root folder) in which the FEDORA process is running in the Tomcat servlet container (usually 'FEDORA').

This interface enables you to search objects and view their components. When opening an object, you can not only view the complete version history but also all datastreams and methods of that object.

The distinction between datastreams and methods has already been introduced; datastreams are representations of the objects in different forms, i.e. a TEI-document with conforming images and metadata records. Methods serve as means to produce virtual respresentations of the object, i.e. when running a dissemination operation the primary datastreams are transformed dynamically into a representation by use of the respective method (for instance a HTML or PDF representation). In the methods' list all assigned Service Definition Objects (SDefs, starting with 'get') can be viewed and run. The default method is to 'get' the whole object, running the default transformation on the default datastream, according to the underlying content model. FEDORA can be configured to add parameters ('locale', 'mode', etc.) to certain methods.
All components of a compound digital object can also be addressed seperately in an URL convention. Datastreams can be viewed with the syntax 'servername/PID/datastream'. One example would be 'http://glossa.uni-graz.at/o:guest.40/METS_SOURCE', resulting in the underlying METS document of the object with the identifier o:guest.40 on the server glossa.uni-graz.at. A dissemination method can also be addressed with the syntax 'servername/PID/SDef/get'. An example would be 'http://glossa.uni-graz.at/o:guest.40/sdef:dfgMETS/get' where the service definition shows the same object in the DFG-Viewer (sdef:dfgMETS). Within the Cirilo client, not all datastreams of an object are visible, two rather important ones are only accessible via the web interface. The METADATA datastream is dynamically resulting from the query in the datastream QUERY and therefore not visible in the client. The METHODS datastream contains an enumeration of the assigned methods.
Adressing objects, datastreams and methods
Object: servername/PID
Example: http://glossa.uni-graz.at/o:guest.40
Datastream: servername/PID/datastream
Example:
http://glossa.uni-graz.at/o:guest.40/METS_SOURCE
Method: servername/PID/SDef/method
http://glossa.uni-graz.at/o:guest.40/sdef:dfgMETS/get
Predefined parameters
The GAMS provides three predefined parameters that can be used to pass information to object or context methods: 'locale', 'mode' and 'context'. They can be used in the STYLESHEET datastreams by including them as params: <xsl:param name="mode"/>
The parameter 'locale' is used to pass language settings and accordingly the
navigation, etc. should be translated. For instance, in the following
example the value 'en' is
passed via the 'locale' parameter to indicate that the language settings are
in English:
https://gams.uni-graz.at/context:hsa?locale=en
GAMS further uses the built in i18n-module of Apache Cocoon to handle multi-language web
presentation. Accordingly, you have to use i18n-tags in your XSL stylesheet
creating the HTML output and maintain a translation list on your server.
The parameter 'mode' is used to pass view specific settings information. For
instance, this parameter can be used to distinguish between 'collection' and
'object' view in a digital collection or in the 'Jahrrechnungen der Stadt
Basel 1535 bis 1610' the 'mode' parameter is used to indicate that the
entries should be presented either in a chronological list view (value
'chrono'), a page view (value 'page') or a table view (value 'tab'). Example
Jahrrechnungen der Stadt Basel 1535 bis 1610:
https://gams.uni-graz.at/context:srbas?mode=chrono
https://gams.uni-graz.at/o:srbas.1537/sdef:TEI/get?mode=tab
The parameter 'context' is used to specify an object’s context. These
contexts are project specific and allow to group and filter objects. For
instance, in the project 'Moralische Wochenschriften' the 'context'
parameter is used to filter certain objects by language and, therefore, the
value 'en' indicates that only objects written in English are displayed:
https://gams.uni-graz.at/archive/objects/context:mws-femalespectator/methods/sdef:Context/get?locale=de&context=en
A more complex example of the use of the 'context' parameter can be found in
the 'Onlineportal der Archäologischen Sammlung'. In this case two pieces of
information are passed via the 'context' parameter. First, that the objects
should be sorted by country (context:arch.g.land), and second, that only
objects from Italy (context:arch.g.land.italien) should be displayed. The
exclamation mark is used to separate the two pieces of information:
https://gams.uni-graz.at/context:arch.g.land.italien?context=context:arch.g.land!context:arch.g.land.italien
It should also be mentioned that there is a fourth predefined parameter
'params' which is used to pass parameters to a query object. This parameter
will be discussed further below under cirilo:Query model. Example:
https://gams.uni-graz.at/archive/objects/query:ufbas.volltext/methods/sdef:Query/get?params=$1|wyn
Tutorial: First steps
In this section, we will introduce you to a few functions you might want to use first. The prerequisite for performing any action with the client is knowing about its persistent identifier (PID) policy, so this subsection is treated first. After that, you can find information on basic repository operations like creation, editing, ingest and organization of digital objects. These operations can be performed when choosing the option 'Edit objects' from the 'File' menu.
How to find objects in the repository
Open the option 'Edit objects' from the 'File' menu. You can find objects by entering a persistent identifier (PID), some text contained in the displayed fields (content model, last update time, and owner) or a part of it and/or using the wildcard "*" in the search field. Then choose either 'Search' or press 'Enter' on your keyboard and a collection of objects is listed. The objects are sorted according to their PID, furthermore also the title, the content model, the last update time, and the owner of the objects are displayed. The options 'Edit' and 'New' apply to one selected item only; 'Delete', 'Replace', 'Export', 'Aggregate' and 'Manage handles' are mass operations performable on more than one object simultaneously. You can select more than one object by keeping pressed either 'Ctrl' or 'Shift' on your keyboard and clicking on the mouse simultaneously.5

How to assign PIDs
Upon creation, every object receives its PID which will remain unchanged throughout its whole life cycle. PIDs are distinguished according to the content model: Context objects have a PID starting with the prefix 'context:', data objects with the prefix 'o:', and query objects with the prefix 'query:'. This is creating a namespace for the respective objects.
PID namespaces
- context:PID - context objects, example: context:bag-correspondence
- o:PID - data objects, example: o:bag.456 (with the subset o:oao.PID for objects with the content model cirilo:Annotation, example: o:oao.1688)
- query:PID - query objects, example: query:bag-persons
The assignment of PIDs can be managed in three ways: a) when creating an object manually via choosing 'File' > 'Edit objects' > 'New', b) when specifying a prefix in the ingest objects dialogue box, c) when referencing the PID in the source document before ingest. a) When creating an object directly in the client by choosing 'File' > 'Edit objects' > 'New', you can enter the PID for context and query objects in the field 'PID' when the respective checkbox is activated. To assign a PID in this way for data objects is only possible if you are logged in as administrator. If there is already an object with the specifid identifier, an error message will occur. When the checkbox is not activated and hence no PID is specified for data objects, the system creates a random one using the current user name and a digit separated by a period. For context objects, creation with a random PID is not possible, the PID has to be specified by the user. b) When choosing 'File' > 'Ingest objects' a PID can be specified if the checkbox is activated; if only one object is ingested, it will receive the exact PID, if more than one object is found for ingest in the directory, the input in the PID field will be used as a prefix and the individual objects receive an additional number following this prefix. If the checkbox is deactivated the client creates a random PID using the current user name and a digit separated by a period. c) When ingesting objects from a directory, you can place the PID in a designated element in the source document. This is possible for TEI (element <idno type="PID"> within <publicationStatement>6), LIDO (<lido:lidoRecID lido:type="PID">), METS (<mods:identifier type="urn">) and RDF (@rdf:about in <void:Dataset>) documents. Important: If an object with the specified identifier is already present in the repository, the existing object will be refreshed with the new content. The only exception are RDF documents, where the content will not be replaced but added in the object. If you do not specify the PID in the source a random one will be created upon ingest. PIDs can contain the following characters:
Characters allowed in PIDs
- Numbers from 1-9
- Characters from a-z (lower case only)
- No special characters apart from . and -
All other characters are not accepted in the input field!
All objects in the GAMS repository also receive a handle during the ingest process, for further information see the respective section.
How to create new objects
To create a new object, select the option 'New' from the bottom in the 'Edit objects' dialogue. First, choose the content model from the drop-down menu. A PID can be specified when choosing a context object or a query object; for data objects, a random PID starting with 'o:' is generated automatically (cf. also the section on How to assign PIDs). The automatic naming of data objects guarantees short, consistent and permanent identification. Additionally, the owner of the object can be chosen from the drop-down menu. All metainformation can be added to the Dublin Core fields. If you want to add one Dublin Core field twice (for instance if you want to add two creators) you can enter all information in one field and separate it with a tilde "~". In the output, two fields will be created. Example: The input "Friedrich Schiller~Johann Wolfgang von Goethe" (see screenshot below) results in this output in the DC datastream: <dc:creator>Friedrich Schiller</dc:creator><dc:creator>Johann Wolfgang von Goethe</dc:creator>.
Create two DC fields by use of ~
Input: Friedrich Schiller~Johann Wolfgang von Goethe
Result:
<dc:creator>Friedrich Schiller</dc:creator>
<dc:creator>Johann Wolfgang von Goethe</dc:creator>
Every object needs to have a PID, an owner and a content model as well as a DC title; these obligatory fields are marked in yellow. If no title is specified, "No Title" will be inserted automatically. The option 'Released for OAI-Harvester' at the bottom is only applicable when you have an OAI interface configured. In this case, the ticking of the box will result in the publication of the object on the OAI interface. 7 After selecting 'Create' a new (empty) object with content model specific datastreams will be created. A popup message will tell you whether your operation was successful or, otherwise, which problems have occurred. When creating a context object, the operation may be finished now; in the case of a data object you may want to finish the creation with the addition of a primary datastream (for instance a TEI document) in the 'Edit' dialogue (see the next section).

How to edit an existing object
To manage, view and change an already existing object in the repository, find your desired object in the 'Edit object' dialogue box (see here) and choose the 'Edit' option from the bottom. The opening dialogue box consists of four tabs: 'Properties', 'System datastreams', 'Content datastreams' and 'Relations'. On the first tab 'Properties', the owner of an object can be changed. The owner of the object can only be changed if the user has administrator rights; the PID of an object can never be changed. To take over your changes, click 'Apply' at the right side.

In the tab 'System datastreams' the content of the datastreams used for system functions can be viewed. As these are necessary for the correct functioning of the object, you should only make changes if you are the administrator. The most system datastreams are not actually stored in the object but referenced from the cirilo:Backbone object (cf. this section). This can be seen from the 'Group' they are in, where 'R' stands for redirect, 'X' is for internal XML data (this will be validated before upload) and 'M' is for managed content (not validated). Images for instance will typically fall under the last category.
Groups
- X: internal XML data
- M: managed content (not validated)
- R: redirect (to a specified location)
The location of the redirected datastreams can be found in the 'Location' column. Consequently, these datastreams can only be viewed by selecting 'Show' at the bottom and can not be changed in the object itself. Instead, when clicking 'Add' you can alter the reference to the datastream, i.e. you can for instance link to another stylesheet in your cirilo:Backbone object or to a document reachable elsewhere via an URL. You can select any datastream in the list and save a local copy by pressing 'Save as' at the bottom.

The tab 'Content datastreams' offers the possibility to create, change and update primary datastreams and other content datastreams in the object. You can for instance add the content of your primary datastream (as mentioned in the section How to create new objects above). In the example below, the primary datastream is a TEI document contained in the TEI_SOURCE stream. You can show and change it by selecting the datastream and clicking 'Edit' at the bottom. Then an XML editor opens, showing the content. After you have made your changes, do not forget to choose 'File' and 'Save' to apply them. You can also update the stream with a finished document from your filesystem by selecting 'Add'. The same is basically true for all content datastreams regardless of their content model. You can select any datastream in the list and save a local copy by pressing 'Save as' at the bottom.

When clicking 'New', you can create a new content datastream for the object. Specify your datastream-ID and label; datastream IDs are by convention in capital letters and only words that are not already in use by the system are accepted (you can not create a second TEI_SOURCE for instance). Choose your version option and your Mime Type (most often 'text/xml'). The new datastream appears immediately in the dialogue box. Content datastreams created in this way can also be deleted by clicking the respective button; datastreams created by the system through the content model can not be deleted. The THUMBNAIL datastream can only be added and shown but not edited. When selecting the DC stream and clicking 'Edit', the Dublin Core metadata of the object can be viewed and edited. This is possible directly in the graphical user interface or in pure XML. To this end, choose 'Edit' in the dialogue box and another window with the XML source of the DC data will open. Click 'Save' and 'Close' to go back to the object.

In the last tab 'Relations', the object can be assigned to one or more context objects (for further explanation of the concept see the section How to organize collections). The field 'Appears in:' shows the current assignments of the object: in our example none. To add a new context object select it in the second field. You can either show all available contexts by entering '*' in the search field or limit the number by entering a specific PID or part of it. When you have found your context, either double click it or select it by simple click and use '+' to add it to the list. When selecting an already assigned context in the first field and clicking 'Delete', the assignment will be removed. Do not forget to click 'Apply' before you close the window!

How to replace the content of one or more objects
As already mentioned, Cirilo is especially designed to being used in mass operations on FEDORA repositories. To edit more than one object, simply select them in the search field of the 'Edit objects' dialogue box as described in this section. Then you have a few options that can be applied to all selected items. You can choose 'Delete', 'Replace', 'Export', 'Aggregate' or 'Refresh'. When you choose 'Delete', one or more selected objects are deleted from the repository. When clicking 'Export', one or more objects can be exported to a specified location in FOXML-format (FEDORA Object xml). The 'Aggregate' option can be applied to context objects only. By selecting it, geo data from all assigned data objects is gathered and aggregated in the context object, where it can be viewed in a map (for details on this operation see the content model description of the cirilo:Context model). The 'Refresh' option refreshes the display of the objects in the current 'Edit objects' dialogue box, i.e. when objects are created, changed, or deleted in the present selection, you can update the displayed information to the latest version. The 'Replace' dialogue box offers the possibility to change a wide variety of objects at once with the same operation. In the first tab 'Dublin Core', you can edit all DC fields of the selected objects. By ticking the box 'Released for OAI-Harvester', the objects will be published via the OAI-interface. The ticking of the box 'Refresh object from source' results in the anew application of all mappings and extractions from the selected objects, according to the selected options in the 'Preferences'. (cf. the sections on semantic enrichment and ingest options). In any case, do not forget to select either 'add' or 'replace' from the drop-down menu, otherwise the element will not be modified!

In the second tab 'Datastream locations', you can change the location of your referenced datastreams. First, select the datastream you want to replace from the drop down; the list only contains datastreams in the group 'R'. Second, you can either enter the new URI location of the datastream or click on the symbol at the end of the line. When clicking on the symbol, a dialogue box opens where you can choose a stylesheet datastream: This list conforms to the stylesheets listed in the 'STYLESHEETS' datastream of the cirilo:Backbone object (only editable for the administrator, see here). Select 'replace' in the drop down and press 'replace' at the bottom to make the changes effective.

In the 'Queries' tab you can enter a SPARQL query: the result of this query is present in the METADATA datastream of the object. A default query is already specified but not visible in the window. To make changes copy or type a new query in the data field and choose 'Replace' in the drop down. The METADATA datastream is created dynamically from the query and therefore not directly visible in the client, but you can view it via the FEDORA search interface. The string '$self' can be used as a placeholder for the PID of the object in question. For details on the format and possibilities for the query, please see the SPARQL specification.

You can assign the selected objects to one or more context objects in the 'Relations' tab. This is carried out similar to when editing one object (cf. How to organize collections), with the difference that the relation will be added to all selected objects and that you have to choose either 'Add' or 'Replace' in the drop-down list, otherwise the objects will remain unmodified.

Under the heading 'Transformations' you can add a transformation scenario to a specific datastream. This differs from the assignment of a stylesheet through the 'Datastream locations' tab in two ways: Because the STYLESHEET is routed in the FEDORA system it can a) be applied to all objects of a project, and b) you can select these stylesheets from within the client from the initializer object. The transformations in this tab on the other hand are used to modify the content of the selected datastream. Choose the datastream and assign your stylesheet from the filesystem. The content of the datastream will be transformed and the result will be saved back to it for all selected objects. This means, you change not only the location from where the datastream is referenced but the content of the datastream in the respective object. Following from that, these transformations can only be applied to content datastreams with the group 'X'. A possible scenario would be to create an XSL stylesheet to transform your existing TEI documents stored in TEI_SOURCE to the latest version of the guidelines. Do not forget to select either 'simulate' or 'apply' from the dropdown to execute the operation!

How to ingest objects
To start a new ingest process, choose 'File' and 'Ingest objects'. The dialogue box allows you to configure mass ingest scenarios for cirilo:dfgMETS and cirilo:TEI objects. Choose one of the two content model types and click either 'From filesystem' (which opens the directory selection dialogue), 'From eXist' (which allows you to connect to an eXist database), or 'From Excel'. All files from the selected directory (including also all sub-directories), database, or spreadsheet will be imported. While ingesting from the filesystem or from eXist is relatively self-explanatory and straightforward, ingesting from an Excel spreadsheet requires some configuration of the ingest scenarios and is explained in detail in the respective section. Files are validated upon ingest, i.e. if the source document is not valid, the ingest process fails and an error message occurs. If you use the ingest function, it is highly recommended to specify your PIDs in the source documents (for further information cf. the section How to assign PIDs). Please note, that if two documents specify the same PID, the first one ingested will be updated with the content of the second one for all content models except for the cirilo:Ontology model for RDF. If more than one RDF document specifies the same PID value in the @rdf:resource of the <void:Dataset> the content of the second one will be added to the first one and will not replace it!
How to determine PIDs in source documents
- TEI: <tei:idno type="PID"> within <publicationStatement>
- LIDO: <lido:lidoRecID lido:type="PID">
- METS: <mods:identifier type="urn">
- RDF: @rdf:about in <void:Dataset>
The DC metadata specified in the ingest dialogue box will be copied for all ingested objects. A log file with details on the process is provided by the client; Either click 'Show log' or open it from the ingest source directory in your filesystem, where it is saved. The ingest of objects can also be simulated. This option is used to detect possible errors in the log files, before actually starting huge mass ingest operations. If you want to run a simulation, tick the corresponding box.

During ingest, the extraction of semantic data and addition of context objects and images can take place; see this section on the activation of this option. The extraction is achieved through the appropriate markup of these entities in the ingested document. Within TEI and LIDO documents you can add images and context objects. Context objects referenced with the appropriate syntax have the effect that the created object is a member of the referenced context. If the context does not exist already, the operation results in the creation of a new context object with the specified name.
Example for the appropriate TEI markup: <tei:ref target="context:demo" type="context">Demo Context</tei:ref>
Example for the appropriate LIDO markup: <lido:term lido:label="context:demo">Demo Context</lido:term>
Thus, when the object context:demo does not exist already, it is created and the TEI or LIDO object is assigned as a member of it. To add images to the TEI object place the file name in the <tei:graphic> element and the image will be added as a separate datastream with the ID from the xml:id attribute in the resulting object: <tei:graphic mimeType="image/jpeg" url="file:///test.jpg" xml:id="IMAGE.1" /> (the same is true for any other MIME-type used with the <tei:media> element, e.g. <tei:media mimeType="text/plain" url="file:///test.txt" xml:id="PLAINTEXT.1" />)
If you reference an image via an URL in the <tei:graphic> element, the image will not be stored in the object but the reference will be used to display the image from the external source. In the LIDO object, create a <lido:resourceSet>, place the file name in the <lido:linkResource> element and the datastream ID in the <lido:resourceID> element:<lido:resourceSet lido:sortorder="1"> <lido:resourceID lido:type="IMAGE">IMAGE.1</lido:resourceID> <lido:resourceRepresentation> <lido:linkResource lido:formatResource="image/jpeg">file:///test.jpg</lido:linkResource> </lido:resourceRepresentation> </lido:resourceSet> With METS objects you can add the images needed for the facsimile representation by adding the respective files in your <mets:fileGrp> with the syntax: <mets:file ID="IMG.1" MIMETYPE="image/jpeg"> <mets:FLocat LOCTYPE="URL" xlink:href="file:///test.jpg"></mets:FLocat> </mets:file> With Ontology objects you can add the images needed for the facsimile representation by adding the respective files in a <schema:image> like this <schema:image> <schema:ImageObject rdf:about="https://gams.uni-graz.at/o:crown.object.1480898/IMAGE.1"> <!-- input file name --> <schema:contentURL>CR_1_E_St_25_Messpunkte.jpg</schema:contentURL> </schema:ImageObject> </schema:image> The ID of the image ist set after last "/" in rdf:about.
Images referenced in this way are taken into the created object as a separate datastream with the PID specified in the ID-attribute of <mets:file>, in this example 'IMG.1'. After ingest the xlink:href of the <mets:file> and the url of the <tei:graphic> and the <lido:linkResource> will be updated to "servername/archive/objects/PID/datastreams/ID-datastream/content" (for instance http://glossa.uni-graz.at/archive/objects/o:guest.40/datastreams/IMG.1/content). This is the location where the image is found within the newly created object.
How to add images and contexts objects through referencing in the TEI source
Place the file name or URL in the @url attribute of the <tei:graphic> element and specify the appropriate Mime-type, add the ID of the image in the attribute xml:id
<tei:graphic mimeType="image/jpeg" url="file:///test.jpg" xml:id="IMAGE.1" />
Place the PID of the context in the @target attribute of the <tei:ref> element, specify the type attribute with 'context' and place the name of the context in the text node of <tei:ref>
<tei:ref target="context:demo" type="context">Demo Context</tei:ref>
How to add images and context objects through referencing in the LIDO source
Place the file name or URL in the <lido:linkResource element>, specifiy the correct Mime-type in the @lido:formatResource attribute and add the ID in the <lido:resourceID> element
<lido:resourceSet lido:sortorder="1"> <lido:resourceID lido:type="IMAGE">IMAGE.1</lido:resourceID> <lido:resourceRepresentation> <lido:linkResource lido:formatResource="image/jpeg">file:///test.jpg</lido:linkResource> </lido:resourceRepresentation> </lido:resourceSet>Place the PID of the context in the @lido:label attribute of the <lido:term> element
<lido:term lido:label="context:demo">Demo Context</lido:term>
How to add images through referencing in the METS source
Place the file name or URL in @xlink:href attribute in the <mets:file> element, specify the ID of the image in the attribute @ID <mets:file ID="IMG.1" MIMETYPE="image/jpeg"> <mets:FLocat LOCTYPE="URL" xlink:href="file:///test.jpg"></mets:FLocat> </mets:file>
How to add images through referencing in the ONTOLOGY source
Place the file name or URL in @rdf:about attribute in the <schema:ImageObject> element, specify the ID of the image after the last / <schema:image> <schema:ImageObject rdf:about="https://gams.uni-graz.at/o:crown.object.1480898/IMAGE.1"> <!-- input file name --> <schema:contentURL>CR_1_E_St_25_Messpunkte.jpg</schema:contentURL> </schema:ImageObject> </schema:image>
Semantic data can be extracted in various ways during the ingest of objects. For further information on this complex operation please see the section How to semantically enrich your data.
How to organize collections
If you have many objects in your repository, it is good sense to organize them in collections. This can be done through the use of the cirilo:Context objects. After creating a context object, other objects can be assigned to it like to a container or folder. You can do so by opening the respective object, choosing the tab 'Relations' and add the context there manually (cf. also the section How to edit an existing object). You can also select various objects in the 'Edit objects' menu, choose 'Replace' and the tab 'Relations' from the dialogue box. Do not forget to tick either 'Replace' or 'Add' in the dropdown menu, otherwise the changes will not be effective (cf. also this section). You can also assign contexts to other contexts, arriving at a whole hierarchical collection structure. If this structure is very complicated, you may wish to create all context objects and the relations between them automatically. Cirilo offers the opportunity to ingest a TEI document containing a taxonomy structure for this purpose; you can also create a new cirilo:TEI object manually and update the content of the datastream afterwards.
A short example for a taxonomy is this one: ... <tei:taxonomy> <tei:category xml:id="context:demo"> <tei:catDesc>Demo Context</tei:catDesc> <tei:category xml:id="context:demo-level1"> <tei:catDesc>Level 1</tei:catDesc> <tei:category xml:id="context:demo-level2"> <tei:catDesc>Level 2</tei:catDesc> </tei:category> ... In this example, you can see how to structure an appropriate TEI taxonomy. Adding nested categories is achieved by placing <tei:category> elements within a <tei:category>. In the xml:id attribute of the <tei:category>, you place the PID of the context object, in the <tei:catDesc> the name. The snippet will result in a context object "context:demo", which has "context:demo-level1" as a member which in turn has "context:demo-level2" as a member. Another possibility to add a context element is to simply reference it somewhere in your cirilo:TEI or cirilo:LIDO object like described in the section How to ingest objects.
How to import and export objects
Export of objects can be performd when choosing 'File' > 'Edit objects' and clicking 'Export' (see here). One or more selected objects will be exported to a specified location in FOXML-format (FEDORA Object xml). To configure the export type, go to 'Preferences' > 'General'. Import of objects is performed by choosing 'File' > 'Import objects'. Currently, the client supports the following formats for import:

By clicking 'From filesystem', you choose the local source location for the import of files. At the end of the process, a popup message will tell you if the operation was successful.
Options
Reset desktop
By default, the client memorizes the coordinates of all opened dialogue boxes and windows and applies them again, when opened the next time. The option 'Reset desktop' resets all window sizes and positions to the default settings and is located in the 'Extras' menu.
Repository location
You can switch to another repository or user by selecting 'Change repository' in the 'File' menu. Just enter the different authentication information in the appearing dialogue box.
Client language
To change the client language (currently German ('de') or English ('en')), enter the appropriate abbreviation in the file cirilo.ini. This file is found in the home directory of the user and stores all data on the client. The respective code snippet reads 'interface.language=de'. The next time the client is opened the language will be changed.
Upgrade repository
Since Cirilo is a continously updated and enhanced software package, this option enables you to download the most recent version of content models. When selecting this option, the client first checks if the content models are up to date; if not, you can upgrade to the latest version by downloading the models from Github and indicating the local directory in the client. The operation will also upgrade all existing objects in the repository to the new version. This option is only executable by a user with admin rights and can be found in the 'Extras' menu.
Reorganize triplestore
When selecting this option the Blazegraph triplestore will be deleted and newly created. This option is only executable by a user with admin rights and can be found in the 'Extras' menu.
Tutorial: Advanced
The 'Preferences' option and how to use it to configure your ingest scenario
In the 'Extras' menu some 'Preferences' for the ingest and edit process can be specified. Everytime a TEI or other primary source document is modified, all extraction processes are applied according to the settings in the preferences. The first tab 'General' gives a) the option to determine the content model which will show up as default when creating a new object through 'Edit objects' and 'New' (cf. How to create new objects), b) the possibility to enter your own handle prefix (cf. How to manage handles), c) the possibility to enter your login name for the Geonames webservice (free registration is possible under http://www.geonames.org/login), and d) to specify the export behaviour of the client ('Archive' contains all datastreams including managed content in binary code, i.e. is completely self-descriptive, 'Public' and 'Migrate' contain only the XML content, managed content is presented either as absolute URLs ('Public') or relative references inside the repository('Migrate').
The tab 'Upload of TEI documents' comprises some options on the behaviour of the client during the ingest of TEI documents. The options are explained in the following.
- 'Overwrite source document with expanded content': Activates/deactivates overwriting of ingest information to the source document in the local file directory, for instance extracted ontology data or geoinformation
- 'Extract Dublin Core metadata': Activates/deactivates the option of extracting Dublin Core metadata from the TEI source using the DC_MAPPING datastream and saving the result to the DC datastream (cf. the section How to semantically enrich your data)
- 'Apply policy for extracting semantic constructs': Activates/deactivates the option of extracting RDF data from the TEI source, either using the RDF_MAPPING datastream and saving the result to the RELS-INT datastream or using the TORDF transformation and saving the result to the Sesame repository and the RDF datastream (cf. the section How to semantically enrich your data)
- 'Create context objects': Activates/deactivates the option to create context objects from the reference within the source document during ingest (cf. the section How to ingest objects)
- 'Execute TEI customization': Activates/deactivates the application of a TOTEI transformation to ingest customized TEI (cf. How to ingest customized TEI)
- 'Create METS datastream': Activates/deactivates the option to create a METS datastream from the information in the TEI document during ingest using the TEITOMETS datastream
- 'Resolve regular expressions': Activates/deactivates the resolving of regular expressions using the REPLACEMENT_RULESET datastream (cf. the example in the section on the cirilo:TEI model)
- 'Upload images': Activates/deactivates the upload of images referenced in the source (cf. the example in the section How to ingest objects)
- 'Resolve SKOS concepts': Activates/deactivates the option of resolving ontology concepts (cf. the section on How to semantically enrich your data)
- 'Resolve placeName elements against geonames.org': Activates/deactivates the option of resolving place names mentioned in the source documents against the web service geonames.org (cf. the section on How to semantically enrich your data); the second option 'Accept elements with geonameID exclusively' limits the resolvement of place names to those ones explicitly carrying an attribute with the geonameID.
- 'Remove empty elements without attributes': Activates/deactivates the removal of empty elements without attributes during ingest from the TEI source

The tab 'Upload of LIDO documents' contains similar options regarding the ingest of cirilo:LIDO objects.
- 'Overwrite source document with expanded content': Activates/deactivates overwriting of ingest information to the source document in the local file directory, for instance extracted ontology data or geoinformation
- 'Extract Dublin Core metadata': Activates/deactivates the option of extracting Dublin Core metadata from the LIDO source using the DC_MAPPING datastream and saving the result to the DC datastream (cf. the section How to semantically enrich your data)
- 'Apply policy for extracting semantic constructs': Activates/deactivates the option of extracting RDF data from the LIDO source, either using the RDF_MAPPING datastream and saving the result to the RELS-INT datastream or using the TORDF transformation and saving the result to the Sesame repository and the RDF datastream (cf. the section How to semantically enrich your data)
- 'Create context objects': Activates/deactivates the option to create context objects from the reference within the source document during ingest (cf. the section How to ingest objects)
- 'Upload images': Activates/deactivates the upload of images referenced in the source (cf. the example in the section How to ingest objects)
- 'Resolve placeName elements against geonames.org': Activates/deactivates the option of resolving place names mentioned in the source documents against the web service geonames.org (cf. the section on How to semantically enrich your data); the second option 'Accept elements with geonameID exclusively' limits the resolvement of place names to those ones explicitly carrying an attribute with the geonameID.
In the tab 'Upload of METS documents', you can specify whether you want to overwrite your local source document with the expanded content produced by the client during ingest.
The tab 'Upload of SKOS documents' offers the possibility to normalize your SKOS documents with the Skosify webservice.
In The tab 'Upload of MEI documents' you can specify a) whether you want to overwrite your local source document with the expanded content produced during ingest, b) whether you want to extract DC metadata, c) whether you want to apply the policy for extracting semantic constructs, and d) whether you want to execute MEI costumization.
Select 'Apply' to take over the changes.
How to manage the initializer object
The initializer object of the client carries the PID cirilo:Backbone. In this object, the default components of the content models are bundled, i.e. all default datastreams and automatic extraction processes are operated from here. The contained datastreams take the label 'R' (for 'redirect') in the group column of all other objects. The 'location' column of the object contains the reference to the location in the initializer object. Following from that, within the cirilo:Backbone object all datastreams carry the label 'X' for 'internal XML data' except for the default PAGE streams which carry 'M' for 'managed content'. In the initializer object, the tab 'System datastreams' contains all datastreams, because there are no content datastreams. For a description of the functions of the datastreams in their respective content models, also consult the section on Cirilo content models.
- RELS-EXT: RELS-EXT record for the initializer object itself
- DC: DC record of the initializer object itself
- KML_TEMPLATE: contains the KML template frame for collecting geo information from assigned objects in context objects
- KML_STYLESHEET: contains the rules for extracting KML data of each assigend object in a context object
- PELAGIOS_TEMPLATE: contains the Pelagios template frame for collecting RDF/XML data from assigned objects in context objects
- PELAGIOS_STYLESHEET: contains the rules for extracting Pelagios data of each assigend object in a context object
- CMIF_TEMPLATE: contains the template frame for collecting CMIF information from assigned objects in context objects
- CMIF_STYLESHEET: contains the rules for extracting CMIF data of each assigend object in a context object
- REPLACEMENT_RULESET: contains the ruleset for textual replacements during ingest in cirilo:TEI models
- TEItoHTML: contains the default stylesheet for the transformation of the TEI_SOURCE or BIBTEX datastream of a cirilo:TEI object to HTML format
- TEItoFO: contains the default stylesheet for the transformation of the TEI_SOURCE or BIBTEX datastream of a cirilo:TEI object to PDF format
- BIBTEXtoHTML: contains the default stylesheet for the transformation of the cirilo:BibTeX model to HTML format
- BIBTEXtoFO: contains the default stylesheet for the transformation of the cirilo:BibTeX model to PDF format
- PAGE-1 and PAGE-2: the two default graphics added to an empty cirilo:dfgMETS object
- MODStoBIBTEX_MAPPING: contains the mapping to create the BIBTEX stream from the MODS section of a cirilo:dfgMETS object
- RDF_MAPPING: contains the mapping to extract RDF information from the TEI_SOURCE of a cirilo:TEI object; the RDF is written into the Mulgara Triplestore
- TORDF: contains a default XSL transformation for the extraction of RDF data from the TEI_SOURCE of a cirilo:TEI object; the RDF is written into the Sesame repository
- TEItoDC_MAPPING: contains the mapping which is employed to extract DC data from the TEI_SOURCE of a cirilo:TEI model
- MODStoDC_MAPPING: contains the mapping which is employed to extract DC data from a MODS record within a cirilo:dfgMETS object
- CONTEXTtoHTML: contains the default stylesheet for the representation of the METADATA datastream of the cirilo:Context model in HTML format
- SKOStoFO: the default stylesheet for the transformation of cirilo:SKOS objects to PDF format
- SKOStoHTML: the default stylesheet for the transformation of cirilo:SKOS objects to HTML format
- TOMETS: contains a default XSL transformation to use when ingesting reduced METS documents
- TOTEI: contains a default XSL transformation for the ingest of customized TEI documents
- TEITOMETS: contains a default XSL transformation for the creation of METS/MODS document from TEI document
- TEItoHSSF: contains a default XSL transformation for creating spreadsheet data from TEI documents
- QUERYtoHSSF: contains a default XSL transformation for creating spreadsheet data from SPARQL query results
- LIDOtoDC_MAPPING: contains the mapping which is employed to extract DC data from the LIDO_SOURCE of a cirilo:LIDO model
- LIDOtoHTML: contains the default stylesheet for the transformation of the LIDO_SOURCE datastream of a cirilo:LIDO object to HTML format
- LIDOtoFO: contains the default stylesheet for the transformation of the LIDO_SOURCE datastream of a cirilo:LIDO object to PDF format
- CONTEXTtoFO: contains the default stylesheet for the transformation of the METADATA datastream of the cirilo:Context model to PDF format
- XML2JSON: contains a transformation which produces JSON in a shared canvas compliant format from TEI and LIDO sources
- METS2JSON: contains a transformation which produces JSON in a shared canvas compliant format from METS documents
- PROPERTIES: contains versioning information on the client and repository
- DATAPROVIDERS: contains a list of OAI providers (cf. the section on OAI harvesting).
- OAItoDC_MAPPING: contains the mapping which is employed to extract DC data from the RECORD datastream of a cirilo:OAIRecord model
-
STYLESHEETS: contains the references to all available user defined stylesheets. All stylesheets recorded here can be used in the 'Edit objects' and 'Replace' dialogue (cf. this section). The record in the datastream looks like this: <stylesheets> <stylesheet href="https://gams.uni-graz.at/context.xsl" label="Context" model="cm:Context" owner="public" type="STYLESHEET"/> <stylesheet href="https://gams.uni-graz.at/styles/teiP5/fo/tei.xsl" label="TEI" model="cm:TEI" owner="guest" type="FO_STYLESHEET"/> ... </stylesheets>
Every stylesheet receives its entry in the list, indicating the location of it (in the '@href' attribute), a custom name in the '@label' attribute, the content model to which it is applied (in the '@model' attribute), the owner in the '@owner' attribute (when set to 'public' the stylesheet will be visible for all users, when set to a specific user only for that user), and the datastream as which the stylesheet can be used (in the '@type' attribute the name of the datastream, i.e. STYLESHEET or FO_STYLESHEET).
When altering the datastreams in the cirilo:Backbone object the changes will affect all objects already stored in the repository and the ones added in the future. cirilo:Environment is a reduced copy of the cirilo:Backbone initializer object and is used as a template for the creation of project specific environments (cf. How to create project specific environments).
If you have configured a project specific environment (like described here), the default datastreams will be referenced from the project backbone object and not from the core initializer object.
How to manage handles
Cirilo offers the possibility to assign handles (http://www.handle.net/) to your objects. To do so you have to register to the infrastructure and set up your handle server. You can find the option when choosing 'File' > 'Edit objects'. Select one or more objects from the object list and press 'Manage handles' at the bottom. The following dialogue box appears:

The first field 'Handle prefix' contains the prefix specified for your institution (e.g. 11471 for the GAMS). If you entered this information in the Preferences the value will be copied from there. The second field 'Project prefix' enables you to create project specific prefixes for collections (for instance 812.10), which will be separated from the general prefix with a '/'. If you activate the checkbox 'Number consecutively', another digit separated by a '.' is added to the identifier. You can enter the starting number in the 'Beginning with' field. If the checkbox is not activated the digit present in the PID of the object is added. To finish the operation press 'Create' and the handles will be created for all selected objects. The resulting handle of the example in the screenshot would be 11471/512.10.1. The object can be retrieved under http://hdl.handle.net/11471/512.10.1 or via the handle browser plugin. To delete handles simply select the objects in the list and press 'Delete' instead. The handle information is also present in the object's metadata in the RELS-EXT datastream and therefore also available for OAI-PMH harvesting. The button 'Get key' opens a window to select your handle server authentication file, which can be obtained from your administrator and is needed to be allowed to add new handles on your server.
How to create project specific environments
Cirilo enables you to create project specific working environments, for instance through specific manifestations of a content model. The client allows you to costumize the mappings for DC or RDF extraction according to your needs. When you choose the 'Create Environment' option in the 'Extras' menu, the following window will open.

You are asked to specifiy a user name. By doing so, three new objects will be created in the repository: a) a project specific context model (cirilo:context.testuser), b) a project specific LIDO model, c) a project specific TEI model (cirilo:TEI.testuser), and d) an object functioning as an initializer object for that project specific environment (cirilo:testuser). All four objects carry the namespace 'cirilo:' and the user name of the project. You can see the resulting objects here:

The user name also appears in the list of user names; when all corresponding objects are deleted, the user will disappear as well. In contrast to other content models, the system datastreams of project specific content models are not referenced from the cirilo:Backbone object but from the initializer object of that environment. In this example, the system datastreams of the 'cirilo:Context.testuser', 'cirilo:LIDO.testuser' and 'cirilo:TEI.testuser' models are referenced from the 'cirilo:testuser' object. Upon creation of an environment, the streams in the 'cirilo:testuser' object contain a copy of the default mappings and stylesheets in the cirilo:Environment object. This is a reduced copy of the cirilo:Backbone object and used as a template for all newly created environments. Now, you can edit the datastreams in the initializer object 'cirilo:testuser' and all objects created with a 'testuser' content model will be assigned their project specific mappings and stylesheets automatically.
You can configure your environment according to your specific project needs. You can for instance copy your stylesheets for the HTML representation of context and TEI objects to the project specific initializer object. To this end copy the needed XSLT transformation either in the STYLESHEET datastream (for the TEI objects) or the CONTEXTtoHTML datastream (for the context objects) of the cirilo:testuser object. When a new object is created with the project specific content models, they will automatically contain the reference to these project specific stylesheets. The same is true for FO transformations and all mappings and extraction procedures. With this feature, Cirilo offers the possibility to encapsulate all project specific transformations and mappings in a single object. This facilitates the management of different projects in the client.
How to ingest text documents and customized TEI
Cirilo enables you to choose a Word or OpenOffice text file (.docx or .odt) as the source of your ingest. When selecting cirilo:TEI in your ingest scenario, the client will convert files with the mentioned file extension in the selected directory (and all directories below) into a TEI document. The conversion process uses the TEI stylesheets (in this case version 7.32.0), which have to be present in a directory on your server (location: SERVERNAME/tei). This transformation is the first step in the ingest process; the resulting basic TEI documents are further treated like any other TEI document. XML/TEI, .docx and .odt can all be present in the selected directory, the client will identify them correctly.
Cirilo also offers the possibility to apply a XSLT to a TEI file during the ingest process which converts customized into standard TEI. You have to select "Execute TEI-customization" in the user preferences - Upload of TEI documents to use this functionality. Your source file has to have a <TEI> element as root, but can contain any elements you like. It is recommended to document your modifications in a TEI.ODD file. The XSLT for the conversion is stored in the TOTEI system datastream, either coming from the project specific environment (if a specific user is logged in or selected as owner for the ingest process) or the cirilo:Backbone initializer object (if an admin user is logged in or no project specific TOTEI datastream is present). After the conversion, the validity of the file is tested against the current TEI P5 schema and the ingest rejected, if the result document does not conform to this specification.
The combination of these two functionalities allows to transform a regular text document into a valid TEI P5 document in the same ingest process: First, the client automatically creates a TEI document from a .docx or .odt file. Second, you can add your own stylesheet in the TOTEI datastream, which will convert this raw TEI into a valid P5 document. The client saves the result of the second transformation in the TEI_SOURCE of the newly created cirilo:TEI object.
How to use the REPLACEMENT_RULESET datastream
This option can be used to apply any textual replacement rules to the TEI_SOURCE of a cirilo:TEI object during ingest, for instance the resolving of specified abbreviations or shorthands. The following example illustrates the use:

The ruleset defines a rule on how to act on the match of a regex pattern, specified in the pattern attribute of <rs:regex>. In the case of the above example, when encountering a string matching the regular expression somewhere in the TEI document, the corresponding TEI element structure will be added. The back reference $1 refers to the first grouping in the regex, back reference $2 to the second grouping. A string like #Max Mustermann# in the TEI source document will result in this sequence in the created object: <persName> <forename>Max</forename> <surname>Mustermann</surname> </persName> The option is activated by ticking 'Resolve regular expressions' in the Preferences.
How to semantically enrich your data
Apart from the basic assignment of objects to a context object (cf. How to organize your collections), the client offers several possibilities to semantically enrich your data. Usually, FEDORA can only make statements and assertions about whole objects or datastreams; with the Cirilo client it is possible to make statements about smaller units like parts of a datastream, as long as these parts carry a unique @xml:id.
Before outlining the actual enrichment of data, a few words on the storage of the extracted data in triplestores is in need. FEDORA itself uses a built-in Mulgara triplestore for the assignment of individual objects to context objects and the handling of RDF (meta)data. As the Mulgara triplestore is rather tightly interconnected with the FEDORA infrastructure, it sometimes does not offer the required flexibility and performance. To fully exploit the possibilities of RDF, an additional openRDF Sesame repository connected through a webservice is used in the GAMS infrastructure. This offers several advantages; Sesame supports the use of SPARQL 1.1 and the representation of complex semantic relations and large ontologies, which allows for the creation of semantic enrichment at a larger scale than on object level. Another triplestore, namely Blazegraph, is integrated into the Open RDF-Sesame Framework for full-text search (for details see the documentation at https://wiki.blazegraph.com/wiki/index.php/GettingStarted).
Triplestores in the GAMS infrastructure
Mulgara: FEDORA's built-in triplestore
Sesame: openRDF repository connected to FEDORA repository via webservice; integrated Blazegraph triplestore for full-text search
DC_MAPPING
The fields in the DC datastream of cirilo:TEI, cirilo:LIDO and cirilo:dfgMETS objects are populated during ingest by means of the DC_MAPPING datastream, if the corresponding option is activated in the 'Preferences' option. This datastream is stored in the cirilo:Backbone object and referenced in all objects, except you use a project specific environment (see this section). The mapping states rules as to how certain fields in the TEI, LIDO or METS source are mapped to the fields of the DC datastream. In the following example you can see how information is extracted from the TEI source and written to the DC datastream:

The metadata mapping states that the <dc:title> element is populated from the TEI <tei:title> element. <mm:map> is used as a wrapper for these rules, in the attribute '@select' the XPath expression of the target element in the source document is added. The '@delimiter' attribute is optional: It specifies how to handle multiple occurences of the same element. If the TEI source contains more than one <tei:title> and the '@delimiter' is specified with ':', the result will be one <dc:title> where both TEI titles appear separated by the delimiter. If there is no delimiter specified, two separate <dc:title> fields will be generated (which is usually not the desired result). The <dc:identifier> element is mandatorily populated with the PID of the created object itself. The result of this example in the DC datastream would look like this:
<oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:dc="http://purl.org/dc/elements/1.1/"> <dc:title>Prophecy of Merlin</dc:title> <dc:publisher>Susan Schreibman</dc:publisher> <dc:identifier>o:guest.34</dc:identifier> </oai_dc:dc>RDF_MAPPING
Another possibility of semantic enrichment using the Cirilo Client is the application of the policy for the extraction of semantic concepts. This option can be activated or deactivated during the ingest of TEI objects in the 'Preferences' option. When applied, the operation uses the TEI source document as an input and creates the new datastream RELS-INT, which contains the extracted RDF triples on the object. This method allows you only to refer the elements in the TEI file in the rdf:about statements. It is thus recommended for TEI files representing data structures instead of text refering to information. The extraction is performed by means of the RDF_MAPPING datastream and writes the result to FEDORA's built-in Mulgara Triplestore. The RDF_MAPPING can contain any mapping you may want to employ for your project. To create project specific mappings, cf. the section on How to create project specific environments. A sample mapping could look like the following:

In this case, the RDF_MAPPING defines a rule to find <persName>-elements in the TEI_SOURCE and to create triples for each of the matched elements. You can add as many rules as you want in your mapping. The namespace 'mm:' is reserved for mapping elements, but other namespace (like 'g2o:' in this example) can be used as well. Within the rule, you can access elements and attributes from the TEI source document in two ways: a) you can use a <mm:map>-element to create literals (in this example <g2o:origName>), or b) you can use the '@rdf:resource' attribute to create resources (in this example <g2o:gndRef>). If not already present, the client constructs IDs for every annotated entity and writes them to the TEI document during ingest. This enables you to track every instance of the entity (like a person name) in the TEI source. The automatically created IDs are called SID (system identifier) to distinguish them from other (manually entered) IDs. Additionally to the result of the rules defined in the RDF_MAPPING, the RELS-INT datastream contains a) all parts of the resource listed as <rel:hasPart> and b) all context assignments of the object as <rel:isPartOf>. The RELS-INT datastream of this example would look like the following:

TORDF
Another possibility to create RDF triples from your TEI or LIDO documents is the use of the TORDF datastream. The datastream contains a XSL transformation extracting RDF/XML data from the TEI_SOURCE or LIDO_SOURCE. Unlike with the RDF_MAPPING, the result is not written to FEDORA's built-in Mulgara Triplestore but to a separate openRDF Sesame repository, which is connected to the FEDORA infrastructure via a webservice. With this method you are free to model your own rdf structure. It is therefore recommended for most use cases, when you feel at home with describing the data to be extracted from the TEI or LIDO in RDF.

This XSL transformation creates a number of RDF triples, all extracted information is present in the RDF datastream of the cirilo:TEI or cirilo:LIDO object respectively. The result of the above sample transformation would start like the following:

Extracting DC and RDF data
DC_MAPPING: extracts DC information via a mapping from the primary source and saves it to the DC datastream (dfgMETS, LIDO and TEI models)
RDF_MAPPING: extracts RDF information via a mapping from the primary source and saves it to the RELS-INT datastream (TEI model only)
TORDF: extracts RDF information via XSLT from the primary source and saves it into the openRDF Sesame repository and to the RDF datastream (TEI and LIDO models)
Resolvement of place names
With Cirilo you can resolve place names mentioned in your TEI or LIDO source using the web service of geonames.org. To this end, simply activate the corresponding option in 'Extras - Preferences'. You have two possibilities to create the geo-information: You can either try to resolve the text of the <tei:placeName> element or the content of the TEI <tei:reg> child element of every <tei:placeName> element against the webservice of geonames.org. The same is possible for <lido:place> and its child-elements. This scenario however is only likely to be successful to a limited extent. If you want to make sure the webservice identifies the location correctly, search for the ID on geonames.org and enter it directly in your source: either in the '@ref' attribute of the <tei:placeName> element like this <tei:placeName ref="http://www.geonames.org/727011">Sofia</tei:placeName>, or the '@lido:geographicalEntity' attribute of the <lido:place> element like this:
<lido:place lido:geographicalEntity="http://www.geonames.org/727011"> <lido:namePlaceSet> <lido:appellationValue>Sofia</lido:appellationValue> </lido:namePlaceSet> </lido:place>This assures that you will get exactly the information you were looking for. This distinction is also reflected in the option 'Accept elements with geonameID exclusively' in the 'Preferences' option; the option enables you to only resolve the place names you have already provided with the geonameID in the '@ref' or '@lido:geographicalEntity' attribute. The result will be a list of place names with the extended information from the webservice written to your document, in this example TEI:
<tei:keywords scheme="cirilo:normalizedPlaceNames"> <tei:list> <tei:item> <tei:placeName xml:id="GN.1"> <tei:country>Bulgaria</tei:country> <tei:settlement>Sofia</tei:settlement> <tei:name ref="http://www.geonames.org/727011" type="fcode:PPLC">Sofia</tei:name> <tei:location> <tei:geo>42.69751 23.32415</tei:geo> </tei:location> </tei:placeName> </tei:item> </tei:list> </tei:keywords>The <tei:list> can contain more than one item, depending on how many place names you have referenced. The '@xml:id' attribute on the <placeName>-element can be generated automatically by the client (if not specified) or entered manually before ingest. In LIDO, the result is reflected as a TEI snippet in the <lido:descriptiveNoteValue> element. Furthermore, the client will add IDs to all occurrences where IDs are not already specified. These IDs are called GID (geographical identifier) in contrast to other manually entered IDs. The addition of the geoinformation to the Mulgara Triplestore or Sesame repository depends on the RDF_MAPPING and TORDF datastreams. If there is a template matching for the place names, they will be written into the triplestore(s). On how to aggregate the geoinformation from various data objects in a cirilo:Context object see this section.
cirilo:Ontology model
With the ontology content model, it is possible to create documents in RDF/XML format and to store them in the Sesame repository. You can enrich your data with references to the created ontology. A sample RDF ontology for persons could look like this:

Then, you have to reference the persons in the TEI document.

Just like with the place names mentioned before, the RDF_MAPPING can contain a rule for the addition of the person names and other information to the RELS-INT datastream and thus to the Mulgara triplestore. In this case, the IDs are specified manually in the TEI document and additional information is gathered through the RDF_MAPPING datastream. The resulting data set in the RELS-INT stream would look like this:

You can also match the person names in your XSL transformation within the TORDF datastream and thus write it to the Sesame repository. The semantic data from both triplestores can be queried with a cirilo:Query object.
cirilo:SKOS model
The cirilo:SKOS content model is used to store a document in SKOS format. It differs from the cirilo:Ontology model mainly in the SKOS-specific methods provided by the GAMS infrastructure. The ontology is saved in a Sesame repository, where concepts can be retrieved easily. In the FEDORA search interface under the heading of the methods list, you can search for concepts with the corresponding markup in the SKOS object by entering the preferred label as a parameter in 'getConceptByPrefLabel' and click 'Run'. Similarly, you can enter an appropriate URI in 'GetConceptbyURI' or an external identifier in 'GetConceptByExternalID'. As a result, you get all information associated with the respective concept. When entering an URI in 'GetConceptRelatives' you can additionally specify the relation and retrieve all matching concepts as a result.

With SPARQL 1.1 it is possible to query multiple sources at the same time. Consequently, you can query the SKOS objects in the Sesame repository and the entries in the Mulgara triplestore simultaneously. The client also creates a list of all resources, that are connected to the object <rel:hasPart> in the RELS-INT datastream. This is a snippet of a sample SKOS ontology:

The SKOS content model enables you to resolve SKOS concepts during ingest of TEI documents. When the corresponding ingest option is activated (see 'Preferences'), the client will search through the TEI or LIDO document and extract all annotated concepts. All information as well as all higher hierarchical levels of the contained concepts will be written to the TEI document, if the levels are appropriately referenced with <skos:broader> in the ontology. The ontology concepts are referenced as an attribute value in your primary TEI source. The client will find the reference, if it occurs in the '@ana' attribute and carries the corresponding namespace annotated in the <tei:keywords> element. If the namespace for instance would be this one: xmlns:tr="https://gams.uni-graz.at/skos/scheme/o:trachsler/#, the appropriate reference would be: ana="tr:102". You can enter two or more concepts separated by a space in one attribute. Furthermore, you have to add the line: <tei:keywords scheme='URIschemaobject'> within <tei:textClass> for all SKOS ontology objects you want to use. The attribute '@scheme' references the ontology object in the repository. The namespace definition is necessary to find the concepts in the '@ana' attributes. Before ingest, the keywords section looks like this:

During the whole operation, the client will add IDs to all occurences where IDs are not already specified (in this case 'TR.1'). Additionally, the client creates a '@corresp' attribute with the reference to the '@xml:id' of the <term<. This annotation in the TEI document makes it possible to track every occurrence of the referenced concept. The concept and all parent-level concepts referenced with <skos:broader> in the ontology will be written as a list of <tei:term>s below the keywords reference in the TEI document. This is the TEI document after ingest:

IDs created automatically by the client
SID: system identifier
GID: geographical identifier
namespace: identifier taking the namespace of the ontology object as an identifier
Important: hard coded identifiers interfering with the above mentioned will be deleted! Do not use the strings SID or GID in your IDs.
cirilo:Query model
So far, semantic data from various sources have been gathered and written to the Mulgara and Sesame triplestores. With the help of the cirilo:Query object you can now process all that information with SPARQL. To this end, create a query object (like described in this section) and enter your query in the QUERY datastream. The SPARQL query has no predefined repository, so you have to use SPARQL 1.1 to be able to use the SERVICE keyword and reference a repository. Additionally, you can query multiple sources at the same time with SERVICE. In the following example a query on the Sesame triplestore at https://gams.uni-graz.at/sesame/sparqlendpoint is created (FEDORA's built in triplestore woulbe addressed by https://gams.uni-graz.at/mulgara/sparqlendpoint).
PREFIX dc:<http://purl.org/dc/elements/1.1/> PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#> PREFIX psys:<http://proton.semanticweb.org/protonsys#> PREFIX tei:<http://www.tei-c.org/ns/1.0> PREFIX bk:<http://gams.uni-graz.at/rem/bookkeeping/> PREFIX owl:<http://www.w3.org/2002/07/owl#> PREFIX xsd:<http://www.w3.org/2001/XMLSchema#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX pext:<http://proton.semanticweb.org/protonext#> PREFIX g2o:<http://gams.uni-graz.at/onto/#> SELECT DISTINCT ?jahr ?konto ?pfad (SUM(?betrag) as ?total) ?ober WHERE { SERVICE <https://gams.uni-graz.at/sesame/sparqlendpoint> { ?o dc:date ?jahr . ?b g2o:partOf ?o ; bk:account ?konto ; bk:amount ?a . ?a bk:num ?betrag . ?konto bk:subAccountOf ?ober . FILTER(sameTerm($ober, $1)) OPTIONAL { ?ober bk:accountPath ?pfad .} } } GROUP BY ?konto ?jahr ?pfad ?ober ORDER BY ?jahr ?pfadAs a placeholder for parameters, you can use $1, $2 and so on. The SPARQL variables starting with '$' and consisting of numbers only are reserved for these parameters and thus excepted from the standard SPARQL syntax (cf. http://www.w3.org/TR/rdf-sparql-query/#QSynVariables). Afterwards, you can run the query through the methods view or call it directly via an URL. You can enter parameters with the syntax '$1|param1;$2|param2' and so on in the methods view:

The same call for the URL would be https://gams.uni-graz.at/archive/objects/query:totalstime/methods/sdef:Query/get?mode=graph¶ms=$1|<https://gams.uni-graz.at/rem/#toplevel>. With cirilo:Query objects you are able to create dynamic indices or KML datasets from your TEI source documents. In fact, you can apply any visualization to the results if they are converted to JSON. The displayed result can be addressed from the STYLESHEET so you can style your output according to your project layout. The result of the above query for instance is visualized in a graph:
How to use context objects to aggregate KML, Pelagios and CorrespSearch data
Context objects in Cirilo can act as aggregators collecting defined data structures from objects in the collection. The functionality can be applied to aggregate KML data for geovisualisation, data dumps for Pelagios and metadata in the Correspondence Metadata Interchange Format. The process is always the same: a) you need a template creating the frame for your data, b) you need an XSL stylesheet specifying what data structure should be created for each object in the collection, and c) you have to create an empty datastream in your context object (Content Datastreams > New) where the result of the operation will be saved. Default values for these datastreams are stored in the cirilo:Backbone object, but it is recommended to create the respective datastreams in your project specific environment and to configure them according to your sources. To do so, simply add the datastreams in your project specific backbone object with the following datastream PIDs (Content Datastreams > New; datastreams will be placed in system datastreams automatically):
- KML: KML_TEMPLATE and KML_STYLESHEET
- Pelagios: PELAGIOS_TEMPLATE and PELAGIOS_STYLESHEET
- CorrespSearch: CMIF_TEMPLATE and CMIF_STYLESHEET

Then, add the datastreams for the result of the transformation in your context object, using the PIDs KML, PELAGIOS and CMIF respectively.

The template datastream just contains the frame where the results of each object will be placed in, for KML for instance it would look like this:

Please note that the k:name element will be filled with the title of your context automatically. The corresponding stylesheet would then create an entry for each object assigned to the context object. The data structure is wrapped in the <entry> element which is for processing only and will be omitted in the result. This enables you also to create entries not having exactly one root element (like for the RDF/XML of Pelagios). A KML stylesheet could look like this:

The result of the transformation in the KML datastream of the context object can be seen here:

To visualize the KML results of your cirilo:Context object on a map, you can employ three options: a) the GAMS KML Viewer (sdef:Map/get), b) the PLATIN Place and Time Navigator (sdef:Map/getPlatin) and c) the DARIAH-DE GeoBrowser 8 (sdef:Map/getDariah).
How to configure an Excel ingest scenario
Simple Excel ingest
The client offers the possibility to ingest TEI objects from an Excel sheet. When opening the option 'Ingest objects', set the value of the content model of the objects to be ingested to 'cirilo:TEI' and choose 'From Excel spreadsheet' at the bottom. The following window will appear:

By clicking '...' you are adding a) the template with mappings defining how to turn the information in the spreadsheet into TEI objects and b) the Excel spreadsheet with your data. You have to store your data in a Microsoft Excel spreadsheet with the extension .xlsx (.xls is not covered) in the first sheet. In the following, two central concepts of processing within the TEI template will be introduced: 'repeat' and 'while'. Each concept is illustrated with an example. In this example spreadsheet data for the repeat-option is displayed:

Now, you create your template specifying which information you would like to include in your resulting TEI.

The first row in the spreadsheet contains the field names that can be used as variables in the TEI template. The first column 'id' for instance can be utilized in the TEI template as '$id'. With the help of the <mm:expr> element and its value attribute you can put the values from the Excel spreadsheet into your TEI template. The input is not restricted to variables or XPath, you can also add Javascript in your selects. In this example, you create two TEI objects, one with the PID 'o:asset.1' and one with the PID 'o:asset.2'. Within these objects, you create the <head>-tag with the name of the department in question: 'ZIM' will appear in 'o:asset.1' and 'ACDH' in 'o:asset.2'. Now the important concept of <mm:repeat> is utilized to iterate over all columns with the name 'forename'; for every column with this name an <item> with the information from the Excel in the <forename>-element will be created. The square brackets in the template indicate that there is more than one column to match. The respective columns in the Excel spreadsheet are distinguished by adding a colon and a number to the column heading. Consequently, the resulting TEI_SOURCE of the object 'o:asset.1' looks like the following:

As you can see, all forenames have been added by the <mm:repeat>. In contrast, the following example illustrates the use of the <mm:while> concept. Instead of having various columns from which information is to be included, the information on the same object is dispersed over various rows.

The condition of the <mm:while> element is recorded in its '@field' attribute. It states that as long as the '$id' stays the same, the data is grouped correctly to the same object. In this example, the two objects 'o:asset1' and 'o:asset.2' are created and all forenames assigned in the rows will be collected in the corresponding objects.

The result is the same as in the previous example:
The use of <mm:repeat> and <mm:while> can be summarized as follows. 'Repeat' means that the specified action will be carried out for all matching variable names; information from more than one column will be included. Repeats can not be nested. 'While' makes it possible to iterate over more than one row as long as the condition (the same id) is true. The result is information of more than one row is added to the same object.
<mm:repeat>: iterates over columns with the same element name
<mm:while>: iterates over rows with the same id
Advanced Excel ingest with semantic enrichment
You can also combine your Excel ingest scenario with the possibilities to semantically enrich your data. This means, if appropriately specified in the document, you can resolve semantic concepts like described in the section How to semantically enrich your data in your Excel scenario. To this end, you have to record semantic concepts and place names in the Excel source sheet:

Now, you can use this information in your TEI template to create the structure for the resolvement of semantic concepts and place names. This is possible because the transformation from Excel to TEI takes place first; therefore, place names and concepts can be resolved during the ingest afterwards. The template must create the TEI structure required for this process like described in the respective sections of semantic enrichment. In this example, the TEI template includes the <keywords> element for semantic concepts and the option for resolvement of place names is activated in the client. The <mm:repeat> creates the <item> and <term> elements with the appropriate 'ana' attribute; the <mm:while> iterates over all place names in the spreadsheet and establishes a <placeName> element in the needed syntax.

After applying this template, the ingest operation will resolve the concepts and place names. For the sake of shortness and clarity, results from only one object, namely 'o:asset.1' will be presented here. The first example shows the resolved concepts in this TEI object.

The second example shows the resulting place name information from geonames.

The concepts and place names in the body of the document receive their IDs and look like this.

With the combination of the Excel ingest function and the options for semantic enrichment, Cirilo provides another powerful tool for creating a large amount of objects with high quality.
How to create METS/MODS documents from image directories
Cirilo enables you to create a DFG-compliant METS/MODS document (cf. the DFG guidelines) from an image directory in two ways: a) you let the client create your METS from the image directory without further metadata from scratch, or b) you provide basic metadata in a simple XML format as the basis of the document. The client will automatically detect, if a basic XML metadata record is present or not.
Simple METS ingest from image directory
Your starting point is a directory containing the image files you want to include in your cirilo:dfgMETS object. Choose this directory as source for your ingest process in the client (cf. How to ingest objects). Directories will be parsed recursively, one object per directory will be created. In the following example, you have 9 pictures:

Since no further metadata is provided from the image directory in this example, the fields for author and title in the file are labelled as "unknown". All images in the directory are added to the METS document in the order of their alphabetical appearance in the file system. After the creation of a simple XML format as an intermediate stage (see below), the XSL transformation stored in the TOMETS datastream is applied to the file. This transformation is becoming effective, when the client encounters the namespace xmlns="http://gams.uni-graz.at/viewer" in the document. The document will then be first transformed with the XSL transformation contained in the datastream TOMETS before being ingested. The TOMETS datastream is either stored in the project specific environment (if a specific user is logged in or selected as owner for the ingest process) or the cirilo:Backbone initializer object (if an admin user is logged in or no project specific TOMETS datastream is present).

Just make sure that the XSL will transform your simplified structure into a DFG-compliant and valid METS/MODS datastream, like in the following example.

Editing of resulting documents
The result of the ingest process will be a cirilo:dfgMETS object in the client, containing all images in the directory as datastreams. The file "mets.xml" will be created in the ingest directory. This file will either contain the simple pre-METS format created by the client as an intermediate stage during ingest or the fully elaborated METS/MODS document present in the METS_SOURCE of the object. Before ingest, you can determine whether you want to store the simple intermediate stage or the fully elaborated METS/MODS document in your local file in the Preferences. If you want to edit your local file in the simple pre-METS intermediate format and not the elaborate METS format, do not activate this option. The simple pre-METS format looks like this:

You can add metadata and structural information manually in your local file and refresh it in the repository. To this end, do not activate the option to overwrite the source document in the 'Preferences'. Now you can add elements and structure to your simplified XML format; make sure you have the appropriate rules defined in your TOMETS XSL transformation. In the example, various information has been added to the original XML file. Note that the PID is always written to the document even if the option is disabled, otherwise it would not be possible to refresh the object in the repository. Naturally, you can also add your metadata directly in the client (see How to edit an existing object). You can also edit the elaborate METS/MODS format, but this is a lot more complicated.

After starting the ingest process again, the object will be refreshed in the repository and the added information will appear in the client.

Advanced METS ingest with metadata from image directory
So far, the workflows assumed that PIDs are assigned automatically by the client. If you want to specify the PID explicitly, you have to provide a minimal XML metadata record before the ingest. To this end, create an XML file which takes the above-mentioned namespace and contains at least a <idno> and a <structure> element (filename does not matter):

The ingest process will take this XML as input and write all the image references into this file as well. Of course you can also provide a more elaborate metadata record at this point and then let the client add the image references during the ingest process.
How to create METS/MODS documents from image directories
You want to use an automatically generated PID: Let the client create your METS file during ingest from the image directory without prior XML
You want to assign a specific PID and add metadata: Provide a basic metadata record with your PID in the same directory as your image files
Important: In any case, if you want to modify your document in the simple pre-METS intermediate format locally, do not activate the option to overwrite the source document in the 'Preferences'!
How to create METS/MODS documents from TEI documents
A second possibility to create a METS/MODS document is to extract the needed (image) data from a TEI document. To use this option, select the cirilo:dfgMETS content model in your ingest scenario and choose an ingest directory containing the TEI document and the respective image files. When doing so, the client will automatically transform the information in the TEI document to a METS/MODS document and store it in the METS_SOURCE of the resulting cirilo:dfgMETS object. The transformation is stored in the TEITOMETS datastream, either located in the cirilo:Backbone object or the project specific backbone object. Just make sure that this transformation results in a valid METS/MODS document, otherwise the document can not be saved. The TEI document is also stored in the resulting cirilo:dfgMETS object as TEI_SOURCE datastream. With this option, it is possible to create a digital object which combines the features of cirilo:dfgMETS and cirilo:TEI: Although the digital object is based on the content model cirilo:dfgMETS, it also contains a TEI_SOURCE and offers the dissemination methods of the cirilo:TEI model. Thus, you can view the facsimiles in a book viewer with METS/MODS and present the transcription from the TEI with the same object.
How to export object data to spreadsheets
Cirilo allows to export data from cirilo:TEI and cirilo:Query objects to spreadsheets. To do so, you have to add a XSL stylesheet transforming your input (TEI or SPARQL results) with the Apache Cocoon HSSF (Horrible Spreadsheet Format) serializer to Gnumeric XML format. The data can then be viewed in spreadsheet software like Microsoft Excel or OpenOffice. The XSL transformation is contained in the HSSF_STYLESHEET datastream in the cirilo:TEI and cirilo:Query models, which is referenced either from the cirilo:Backbone object or the project specific backbone object. There, the datastreams are called TEItoHSSF and QUERYtoHSSF respectively. Here you can see a snippet of a possible transformation:

The result can be called with the method 'getHSSF'. In this example it would produce this spreadsheet:

How to use Cirilo as an OAI harvester
The client can act as an OAI harvester. To this end, you have to configure your data source (either an OAI interface or a OAI 2.0 compliant XML file) in the DATAPROVIDERS datastream in the cirilo:Backbone object. At the top of the file, the location for the logfiles is indicated (usually C:\logs). Make sure you create this location on your local machine or enter another desired location; This is the place where logs for the harvesting process will be stored. For each provider, the following information has to be entered: <repository name="GLOSSA" state="active"> <serviceprovider>http://glossa.uni-graz.at:8081/oaiprovider</serviceprovider> <metadataprefix>oai_europeana</metadataprefix> <updated>2015-07-20 15:51:23.194</updated> <model>cirilo:OAIRecord</model> <url>./oai:metadata//europeana:isShownAt</url> <thumbnail>./oai:metadata//europeana:object</thumbnail> <owner>oaiprovider</owner> <constraints>contains(.//dc:subject,'Hüttenbrenner')</constraints> </repository> Each repository has to be given a name in the @name attribute and an active state to be used as a provider. The element <serviceprovider> contains either the reference to the OAI-PMH interface or the reference to a file to be used as source. The <metadataprefix> element specifies the prefix used by the source repository. The <updated> element is created automatically by the client. In the <model> element you can specify the model that the harvested objects will take in your own repository (in this case of course the designated cirilo:OAIRecord model). The <url> element contains the XPath pointing to the external location of the data source; this information will be copied in the URL datastream of the newly created cirilo:OAIRecord object. The <thumbnail> element contains the XPath expression pointing to a thumbnail of the object (mandatory). If you want to specify the location for the thumbnail to be created not as a relative path expression in the source but an absolute URI location, place '$' in front of that URI in the thumbnail tag. <owner> specifies the owner of the newly created cirilo:OAIRecord objects in your own repository (mandatory for FEDORA). In the <constraints> element you can enter optional constraints conditioning the harvesting process: for instance a keyword in the title, a place in the dc:coverage or a time period in dc:date. This allows the selection of objects from an OAI interface or file. After configuring your dataprovider, choose the option 'Harvest metadata' from the 'Extras' menu. Now choose your dataprovider and press 'Collect' at the bottom. The client will then evaluate the information on the interface or in the file and create a cirilo:OAIRecord object for every OAI record found (and matching your constraints). In this way, you can integrate external data sources into your own repository.
How to use Cirilo for statistical analyses
To create statisticial analyses like network analysis or topic modelling, employ the cirilo:R content model. In the RSCRIPT datastream you can store code either in R or Python producing your results. In this code, you need to include the two variables 'dataframe' and 'output'. Then, the client will take the datasets for analysis from the <dataframe> elements in the DATASETS datastream and will write the output to the PDF_STREAM when requested. The <dataframe> elements need to contain the URL of the dataset in the @rdf:resource attribute and an @xml:id to select the dataset in the output (since the value of @xml:id results in a datastream, it has to conform to the restrictions for generating PIDs). To run the analysis, call the sdef:R/compute method and add the value of the @xml:id of the requested dataset in the mode parameter. Then the R or Python code will be executed and the result displayed dynamically as a PDF. If you want to save the result of this as the default display option of the object, add '/default' in the parameter 'mode'. The sdef:R/get method will either return this saved default PDF (without a given @xml:id in the parameter) or the saved PDF with the corresponding dataset ID, when requesting it with the @xml:id. This method will NOT run the transformation on the fly like sdef:R/compute, but only display the static result.
How to use GAMS as an annotation framework
This chapter introduces the possibility to use the GAMS infrastructure as an annotation framework. To this end, you can use an OAC compliant webservice on the server side and an annotation plugin on the client side. This integration enables the storage of annotations either in a FEDORA repository (version 3.x) or locally. To make use of this feature, you need a) the server-side installation of the annotation webservice and b) the client-side application of an annotation plugin (in this example AnnotatorJS version 1.2). The webservice supports annotation in compliance with the Open Annotation Data Model.
Server-side installation
System requirements for the installation are a java servlet container with Java 1.8 (for instance Apache Tomcat from version 7.x). All authentication mechanisms of the servlet container can be employed in the framework. To start with the installation, deploy the file annotator.war in your servlet container. The configuration of the webservice is carried out in the file CATALINA_HOME/webapps/WEB-INF/servlet.properties (for the sake of clarity, we will use CATALINA_HOME i.e. Tomcat as the name of the servlet container, but of course this can differ depending on which container you are using). The following properties can be configured:
- TRIPLESTORE_LOCATION: directory used as storage of the JENA-triplestore employed by the annotation webservice, for instance /data/annotator/triplestore (make sure that the container process has write permissions on this directory)
- OBJECT_LOCATION: directory used to store the annotation objects (make sure that the container process has write permissions on this directory)
- UUID_PREFIX: when generating UUIDs for the annotations, this prefix will be added for all PIDs
- FEDORA_SERVICE: reference to the FEDORA management API (for instance https://gams.uni-graz.at/archive)
- FEDORA_USER and FEDORA_PASSWORD: username and password of the repository account which should be used for creating the annotation objects in the repository (with the content model cm:Annotation).
The last 3 properties (starting with FEDORA) are mandatory, if you want to use the webservice in combination with a FEDORA 3.x repository.
To edit the authentication information, use the file CATALINA_HOME/webapps/WEB-INF/users.xml. There you can define different authentication scenarios for separate object realms. Basically, all users authenticated through the container can create, edit and delete their own annotations. In addition, users with the property hasSecurityPrincipal can do so for annotations of the whole realm. The property deny excludes the selected user from all operations of the realm. Example: <rdf:RDF xmlns:rdf=" ... " xmlns:oax=" ... "> <rdf:Description rdf:about="urn:uuid:gams:at:realm:default"> <oax:hasSecurityPrincipal rdf:resource="urn:uuid:gams:at:account:admin"/> <oax:deny rdf:resource="urn:uuid:gams:at:account:joe" /> </rdf:Description> </rdf:RDF>
The webservice supports the following service calls via AJAX and POST request:
- add: creation of an annotation object (with a new PID) if you place the param “persistor” with the value “Repository” in your request, the annotation object will be saved to the FEDORA repository; otherwise it will be saved locally
- del: deletion of an annotation object
- edit: editing of the text of an annotation object
- get: list all annotations of an annotation target (as a JSON array)
In addition, the framework supports the GET requests describe and
sparql:
http://[server]/annotator/rest/service/describe gives
information on the status of the annotation framework
http://[server]/annotator/rest/service/sparql? query=[SPARQL-Query] can be
used to send a SPARQL 1.1 query to JENA triplestore containing all the
annotations.
Sample requests can be obtained from http://glossa.uni-graz.at/annotation/index.html and http://glossa.uni-graz.at/annotation/ajax-ex.html (show HTML source) The file annotator.war can be downloaded from http://glossa.uni-graz.at/annotation/annotator.war.
Client-side application
The client-side application of the annotation framework needs the following functionalities:
- Annotations of a specific webpage have to be requested from the server (GET endpoint)
- Annotations have to be added to the correct place on the webpage
- It has to be indicated to the user that annotations are available for a section of the webpage
- The annotations have to be displayed to the user
- The interface has to support the selection of sections or zones on the webpage for annotation
- The selected sections or zones need to be uniquely and persistently identifiable
- The user interface should allow reading, adding, changing and deleting of annotations (conforming to the above defined services of the webservice)
- Error messages returned from the server have to be handled (for instance lack of permissions to add, update or delete an annotation)
The current client-side annotation application is based on the open source Javascript libary AnnotatorJS (version 1.2.10). The application allows for all of the above mentioned requirements, but point 6. As AnnotatorJS adds annotations based on the DOM structure of an HTML document, the client-side application does not guarantee persistence of an annotation. It is currently only a test application for the server-side application. To use AnnotatorJS in this environment you have to add to your HTML: a) annotator.js and annotator.css files (version 1.2.10), b) JQuery, Version 1.11.3+, and c) customized Javascript code managing the annotations, either in a separate JS file or directly in your HTML.
On page load, you have to check if there are already existing annotations for the current page. To this end, request the annotations of the current page from the GET endpoint of the server via an Ajax call and load them into an AnnotatorJS object. Please note that currently AnnotatorJS is not able to load Open Annotation compliant data directly; for that purpose you have to change the data format according to AnnotatorJS requirements. To create, update or delete annotations, use the respective three events described in the AnnotatorJS documentation (http://docs.annotatorjs.org/en/v1.2.x/hacking/plugin-development.html):
- annotationCreated: is executed after an annotation is created in the interface; a JSON is prepared and sent via Ajax to the ADD endpoint of the webservice
- annotationDeleted: is executed after an annotation is deleted in the interface; a JSON with the PID of the annotation is sent via Ajax to the DEL endpoint of the webservice
- annotationUpdated: is executed after an annotation has been updated in the interface; a JSON with the PID und the updated text is sent via Ajax to the EDIT endpoint of the webservice
Please note again that you may have to convert the AnnotatorJS output before sending it to the webservice, if you want to save Open Annotation compliant annotations.
References
AnnotatorJS. http://annotatorjs.org (2016-10-20)
Apache Jena. http://jena.apache.org (2016-10-20)
Apache Tomcat. http://tomcat.apache.org (2016-10-20)
BibTeX. http://www.bibtex.org (2014-04-25)
Blazegraph. https://wiki.blazegraph.com/wiki/index.php/GettingStarted (2014-08-14)
CIDOC-CRM: Comité international pour la documentation - Conceptual Reference Model. http://www.cidoc-crm.org (2015-09-14)
CMIF: Correspondence Metadata Interchange format. http://correspsearch.bbaw.de//index.xql?id=participate_cmi-format&l=de (2016-05-11)
DARIAH-DE GeoBrowser. http://geobrowser.de.dariah.eu (2015-09-15)
Data Seal of Approval. http://datasealofapproval.org/en (2014-04-25)
DC: Dublin Core. http://dublincore.org (2014-04-25)
DFG-Viewer. http://www.dfg-viewer.de (2014-04-25)
DRAMBORA. http://www.repositoryaudit.eu/ (2014-04-17)
FEDORA Commons. http://fedora-commons.org (2014-04-25)
FEDORA Documentation. https://wiki.duraspace.org/display/FEDORA/All+Documentation (2014-04-25)
FEDORA. An Architecture for Complex Objects and their Relationships. Carl Lagoze. Sandy Payette. Edwin Shin. Chris Wilper. http://arxiv.org/ftp/cs/papers/0501/0501012.pdf (2014-04-25)
Gnumeric XML format. http://www.jfree.org/jworkbook/download/gnumeric-xml.pdf (2015-04-08)
Gnumeric XML schema. http://git.gnome.org/cgit/gnumeric/plain/gnumeric.xsd (2015-04-08)
Handle. http://www.handle.net (2014-12-17)
HSSF serializer. http://cocoon.apache.org/2.1/userdocs/xls-serializer.html (2015-04-08)
i18n Transformer. https://cocoon.apache.org/2.1/userdocs/i18nTransformer.html (2017-04-10)
Java Runtime Evironment (JRE). www.java.com (2014-04-25)
JSON: Javascript Object Notation. http://www.json.org (2016-10-20)
KML: Keyhole Markup Language. https://developers.google.com/kml/documentation (2014-04-25)
Kriterienkatalog vertrauenswürdige digitale Archive. nestor. http://files.d-nb.de/nestor/materialien/nestor_mat_08.pdf (2014-04-25)
LaTeX. https://www.latex-project.org (2016-10-20)
LIDO: Lightweight Information Describing Objects. http://network.icom.museum/cidoc/working-groups/lido/lido-technical/specification (2015-09-14)
MEI: Music Encoding Initiative. http://music-encoding.org (2016-10-20)
METS: Metadata Encoding and Transmission Standard. http://www.loc.gov/standards/mets (2014-04-25)
MODS: Metadata Object Description Schema. http://www.loc.gov/standards/mods (2014-04-25)
Mulgara Semantic Store. http://mulgara.org (2014-04-25)
OAI: Open Archives Initiative. http://www.openarchives.org (2014-04-25)
OAI-PMH: Protocol for Metadata Harvesting. http://www.openarchives.org/pmh (2014-04-25)
Open Annotation Data Model. http://www.openannotation.org/spec/core (2016-10-20)
Pelagios. http://commons.pelagios.org (2016-05-11)
PLATIN: Place and Time Navigator. https://github.com/skruse/PLATIN (2015-09-15)
QR. http://www.qrcode.com (2014-08-18)
R. https://www.r-project.org (2016-10-20)
RDF: Resource Description Framework. http://www.w3.org/RDF (2014-05-20)
Reference Model for an Open Archival Information System (OAIS). The Consultative Committee for Space Data Systems. http://public.ccsds.org/sites/cwe/rids/Lists/CCSDS%206500P11/Attachments/650x0p11.pdf (2014-04-25)
Sesame repository. http://www.openrdf.org (2014-04-25)
SKOS: Simple Knowledge Organization System. http://www.w3.org/2004/02/skos (2014-04-25)
Skosify. https://code.google.com/archive/p/skosify (2016-05-11)
SPARQL Query Language for RDF. http://www.w3.org/TR/rdf-sparql-query (2014-04-25)
StoryMapJS. https://storymap.knightlab.com/ (2017-04-10)
TEI: Text Encoding Initiative. http://tei-c.org (2014-04-25)
Trusted Digital Repositories: Attributes and Responsibilities. Research Libraries Group (RLG). http://www.oclc.org/research/activities/past/rlg/trustedrep/repositories.pdf (2014-04-25)
UUID: Universally Unique Identifier. https://tools.ietf.org/html/rfc4122 (2016-10-20)
Versioning Machine. http://v-machine.org (2014-04-25)
Voyant Tools. http://voyant-tools.org (2014-04-25)
1 Cirilo [kɪʀ'ɪʟɔ] is the name of a character from Umberto Giordano's opera "Fedora".
2 For further information on the FEDORA repository system and especially the object model the Wiki of FEDORA can highly be recommended (select your version here: https://wiki.duraspace.org/display/FEDORA/All+Documentation).
3 Datastream names always appear in capital letters.
4 Please note that you have to register your server to load KML from other sources in the DARIAH-DE GeoBrowser. Contact information is available at the website.
5 Basically, the client will show any object stored in the connected repository, as long as it has a RELS-EXT (see here) datastream and either one of the Cirilo content models or the cm:DefaultContentModel1.0 is assigned. Additionally, to view the basic metadata in the dialogues it is necessary to have a title assigned in the DC record. Full functionality can however only be offered for objects created with the client.
6 Please note that the TEI schema is rather strict with the element <idno>; for instance it can not have a <p> element as a sibling.
7 The Open Archives Initiative maintains a protocol for metadata harvesting (OAI-PMH).
8 Please note that you have to register your server to load KML from other sources in the DARIAH-DE GeoBrowser. Contact information is available at the website.